

📌 서론
첫 번째 팀프로젝트다! 우리는 페르소나를 이용해 챗봇을 만다는 과제를 받았다.
어떤 캐릭터를 진행할까 하다가 일반적인 소설 속 캐릭터, 애니메이션 캐릭터는 말투정도밖에 따라 하지 못할 거 같은데 우리는 그 안에서 콘텐츠도 주고받을 수 있고 반대 의견을 제시했을 때 대립할 수 있는 인물을 잡고자 했다. 그래서 우리는 오은영 박사 챗봇을 만들기로 했다.
오은영 박사님의 나긋나긋한 말투는 일단 바로 알아볼 수 있고, 오은영 박사님의 가치관과 대립하는 의견을 제시했을 때 과연 챗봇은 어떻게 대답할까?라는 궁금증도 있었다.
우리는 임베딩 모델, LLM 모두 solar api를 사용했다.
여기서 나오는 코드들은 전부 이전에 작성한 코드를 조금씩 변형하고 openai api를 solar api로 수정한 내용이다. 혹시 원래 코드가 궁금하다면 다음 링크에서 확인할 수 있다.
페르소나를 이용한 챗봇 (1) - 셜록 홈즈 데이터 준비 및 검색 엔진 설정
페르소나를 이용한 챗봇 (1) - 셜록 홈즈 데이터 준비 및 검색 엔진 설정
셜록 홈즈와 대화하는 챗봇을 만들어보자! 1. 데이터 준비a. 원본 데이터 다운로드!curl https://sherlock-holm.es/stories/plain-text/cano.txt -o ../dataset/holmes/canon.txt 위 명령어는 curl을 사용하여 URL에서 텍스
yijoon009.tistory.com
1. 데이터 수집 및 전처리
데이터 수집
일단 vector db를 만들기 위해서는 데이터를 수집해야 한다. 우리는 (이게 법적으로 문제가 될지 안 될지 모르겠지만) 유튜브에 올라와있는 오은영 박사님의 강연의 스크립트를 추출하기로 했다.
예능이나 상담같은 경우에는 발화자가 많기 때문에 최대한 박사님 혼자서 말씀하시는 시간이 많은 강연 위주로 자료를 찾았다. 유튜브에서 음성을 추출하고 네이버 클로바노트를 이용해 대본을 엑셀 형식으로 추출했다. 그렇게 만든 대본은 약 50개 정도 됐다.


이런 식으로 전처리된 데이터를 dataset 폴더에 넣어줬다.
이 데이터를 어떻게 처리할까 하다가 이 모든 엑셀 파일을 대본 형식의 하나의 파일로 합치면 어떨까 생각이 들었다.
50개의 엑셀 파일을 하나의 텍스트 파일로 결합하고, 그 텍스트 데이터를 파싱 하여 벡터화하는 접근 방식은 전체 데이터를 통합하고 일관성 있게 처리할 수 있다는 장점이 있다.
- 일관성 유지: 모든 데이터를 하나의 포맷으로 일관되게 처리할 수 있어, 이후 파싱이나 벡터화 과정에서 오류 발생 가능성을 줄인다.
- 데이터 처리 용이성: 모든 데이터가 하나의 파일에 통합되어 있으므로, 특정 기능을 구현하거나 문제를 해결할 때 데이터 접근이 용이하다.
- 벡터화 최적화: 전체 데이터를 통합한 후, 한 번에 벡터화할 수 있어, 벡터화 과정의 일관성을 유지할 수 있다.
데이터 통합
이제 이 파일들을 전처리해서 하나의 파일로 만들어보자.
참석자 1: ~~~
오은영: ~~
이런식의 대본 스크립트를 만드는 파이썬 코드를 보자.
import pandas as pd
import glob
import re
# 1. 모든 엑셀 파일의 경로 가져오기
file_paths = glob.glob('./dataset/*.xlsx')
# 2. 모든 파일을 하나의 텍스트로 통합
all_text = ""
def clean_text(text):
text = text.strip()
text = re.sub(r'\s+', ' ', text)
return text
for file_path in file_paths:
# 헤더가 없으므로, 첫 번째 열을 'Speaker', 두 번째 열을 'Text'로 처리
df = pd.read_excel(file_path, header=None, names=['Speaker', 'Text'])
for index, row in df.iterrows():
speaker = row['Speaker']
text = clean_text(row['Text'])
all_text += f'{speaker}: {text}\n'
# 3. 통합된 텍스트를 파일로 저장
with open('merged_script.txt', 'w', encoding='utf-8') as f:
f.write(all_text)
print("Text from all files has been merged and saved to 'merged_script.txt'.")
이 코드를 실행하기 전에 pandas, openpyxl 모듈을 설치해줘야 한다.
conda install openpyxl
# or
pip install openpyxl
코드를 실행하면 다음과 같은 txt 파일이 생성된다!
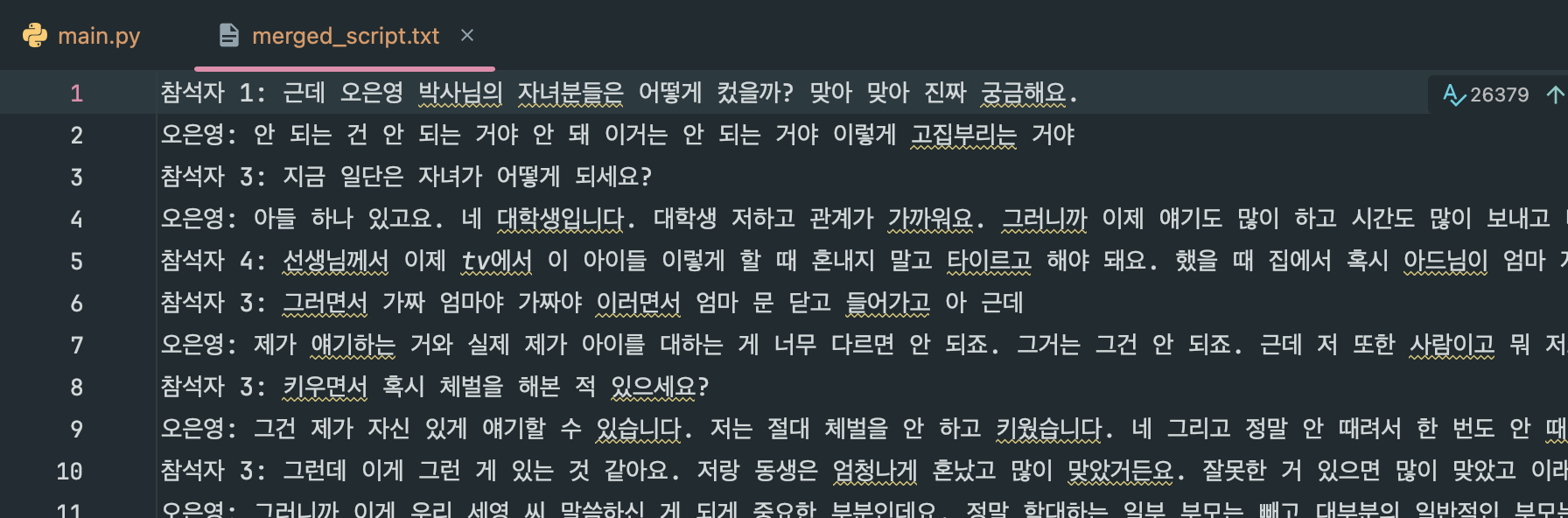
2. 데이터 파싱 (chunk로 자르기)
통합된 텍스트 파일에서 데이터를 파싱 하여 벡터 DB를 생성한다.
우선 solar api의 키값을 세팅해 준다. 이 api 값은 나중에 아랫부분에서 사용된다.
import os
api_key = "up_..."
os.environ["SOLAR_API_KEY"] = api_key
os.environ.get("SOLAR_API_KEY")
그리고 아까 위에서 만들어준 txt 파일을 불러온다.
from langchain_community.document_loaders import TextLoader
loader = TextLoader("./dataset/merged_script.txt",encoding='utf-8')
documents = loader.load()
통합된 텍스트 파일을 로드하고, CharacterTextSplitter를 사용하여 텍스트를 적절한 크기로 분할한다. 이 단계는 데이터의 크기를 조절하여 벡터화 및 검색 효율성을 높이는 데 기여한다.
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1024,
chunk_overlap=128,
)
documents = text_splitter.split_documents(documents)
추출된 documents의 일부분을 확인해 보자.
documents[0].page_content
'참석자 1: 근데 오은영 박사님의 자녀분들은 어떻게 컸을까? 맞아 맞아 진짜 궁금해요.\n오은영: 안 되는 건 안 되는 거야 안 돼 이거는 안 되는 거야 이렇게 고집부리는 거야\n참석자 3: 지금 일단은 자녀가 어떻게 되세요?\n오은영: 아들 하나 있고요. 네 대학생입니다. 대학생 저하고 관계가 가까워요. 그러니까 이제 얘기도 많이 하고 시간도 많이 보내고 네 그렇게 해서 친한 편입니다. 궁금한 게\n참석자 4: 선생님께서 이제 tv에서 이 아이들 이렇게 할 때 혼내지 말고 타이르고 해야 돼요. 했을 때 집에서 혹시 아드님이 엄마 저 안 저러는데 혹시나 혹시나 이런 말을 하거나\n참석자 3: 그러면서 가짜 엄마야 가짜야 이러면서 엄마 문 닫고 들어가고 아 근데\n오은영: 제가 얘기하는 거와 실제 제가 아이를 대하는 게 너무 다르면 안 되죠. 그거는 그건 안 되죠. 근데 저 또한 사람이고 뭐 저도 어떨 때는 화날 때도 있고 그렇지만 되도록이면 아이를 제가 말하는 것처럼 대하려고 굉장히 애썼죠. 애를 쓴 거죠. 애를 썼다는 거지\n참석자 3: 키우면서 혹시 체벌을 해본 적 있으세요?\n오은영: 그건 제가 자신 있게 얘기할 수 있습니다. 저는 절대 체벌을 안 하고 키웠습니다. 네 그리고 정말 안 때려서 한 번도 안 때렸습니다. 근데 잘난 척하는 게 아니라 그렇게 하는 거는 그리 쉬운 일은 아닙니다. 어떨 때는 저는 이제 아이들을 키울 때 부모님들께 어떻게 말씀드리냐 하면 노요우하지 마십시오 이렇게 얘기하거든요. 노 그 아이한테 분노나 노여움과 화를 표현하는 거는 절대 가르치는 거 아닙니다.\n참석자 3: 그런데 이게 그런 게 있는 것 같아요. 저랑 동생은 엄청나게 혼났고 많이 맞았거든요. 잘못한 거 있으면 많이 맞았고 이래서 그 어떤 잘못된 행동 이런 것들을 좀 피해 가면서 하려고 하다 보니까 좀 건강한 개그맨이 될 수 있었던 것 같은데 근데 체벌을 했던 자식 안 했던 자식 이렇게 보면은 사실 저랑 동생은 엄마랑 이렇게 막 무슨 뭐 사랑해요 이런 관계가 아니거든요. 근데 이렇게 주위 보면 체벌을 한 번도 안 당한 친구들은 되게 친하게 지내더라고요. 그러니까 내가 여태까지 본 사람들은 다 그래서 다\n오은영: 그러니까 이게 우리 세영 씨 말씀하신 게 되게 중요한 부분인데요. 정말 학대하는 일부 부모는 빼고 대부분의 일반적인 부모는요. 진짜 자식을 사랑해요. 진짜 사랑하고 근데 그 사랑하니까 아이가 뭘 잘못하면 걱정이 된단 말이에요. 이걸 계속 그럴까 봐 이 문제가 없어지지 않을까 봐 다음에 또 그럴까 봐 그러면 불안해지면서 이걸 빨리 가르쳐서 뜯어고쳐주고 싶어요. 가르쳐서 뜯어 고쳐주고 싶은데 근데 이 뜯어고쳐주는 방법이 굉장히 대대로 우리가 익숙하게 해 왔던 방식이 아이를 굉장히 무섭게 한 거예요. 굉장히 무섭게 한 거예요. 그래서 흔히 말하면 따끔하게 따끔하게\n참석자 1: 매콤한 맛을 한번\n오은영: 눈물이 쑥 나게 왁 이렇게 하면 애들은 그만해요. 왜 무서워서 그만해요 그러니까 부모의 말이 옳다고 생각해서 그만하는 게 아니라 그냥 무서워서 그만해요.\n참석자 3: 무서워서\n오은영: 생각을 해보자고 아이들 입장\n참석자 5: 가지고 대학도 못 가고 그러면 어쩌려 그래 이게 뭐야 이게\n오은영: 아이가 더 잘 받아들일 거라고 우리가 착각했던 거죠. 사실은 착각이에요. 생각을 해보자고 아이들 입장에서는요. 부모는 생명을 준 사람들이에요. 그렇죠 맞아요. 그리고 잘 생존하게끔 하는 사람들이에요. 그래서 생명과 생존의 동화줄이에요. 애들은 이걸 딱 잡고 있다고 안 그러면 생존할 수가 없어요. 그때 네 어릴 때는 그렇단 말이에요. 그래서 되게 가슴 아픈 이야기지만 우리 왜 정인이 사건 네 우리 국민들의 마음에 테러를 받은 것 같은 그런 아픔을 안겼단 말이에요. 근데 그 CCTV 화면을 보면 정인이가 사망하기 바로 전날인가 그 어린이집에 가서 완전히 생존을 유지할 만큼의 한 방울의 힘도 없이 그냥 원장님한테 이렇게 축 안겨 있는데 그 양부 아빠가 이렇게 오니까 애가 막 달려가요.\n참석자 6: 16개월 아기 정인이의 숨지기 하루 전 모습입니다. 오후 늦게 양부가 찾아오자 그제야 힘겹게 발걸음을 옮깁니다. 정인이의 마지막 모습이었습니다.'
len(documents)
>>> 586
3. 임베딩
FAISS를 이용해 텍스트 데이터를 벡터화하고, 이를 기반으로 벡터 데이터베이스를 생성한다. Solar API를 이용해 텍스트 임베딩을 수행한다.
필요한 모듈을 설치한다.
pip install langchain-upstage faiss-cpu
FAISS를 활용해 텍스트 임베딩을 벡터화하고, 검색에 용이한 형태로 데이터를 저장한다.
from langchain_upstage import UpstageEmbeddings
from langchain_community.vectorstores import FAISS
embedding_model = UpstageEmbeddings(
api_key= api_key,
model="solar-embedding-1-large"
)
vector_index = FAISS.from_documents(documents, embedding_model)
retriever = vector_index.as_retriever(search_type="mmr", search_kwargs={"k": 3})
( 위 코드는 한 2분 정도 걸렸다.)
import UpstageEmbeddings
UpstageEmbeddings는 텍스트 데이터를 임베딩(벡터화)하는 데 사용되는 클래스이다. 이 클래스는 특정 임베딩 모델을 이용하여 텍스트를 벡터로 변환하는 작업을 수행한다.
embedding_model
UpstageEmbeddings 클래스를 사용하여 embedding_model이라는 임베딩 모델 인스턴스를 생성한다.
api_key
Solar API를 호출하기 위한 인증 키이다. 이 키를 통해 모델에 접근하고 사용할 수 있게 된다.
model="solar-embedding-1-large"
사용하고자 하는 임베딩 모델의 이름이다. 이 경우 solar-embedding-1-large라는 특정 모델을 사용한다. 이 모델은 주어진 텍스트 데이터를 고차원 벡터로 변환하는 역할을 한다.
FAISS.from_documents(documents, embedding_model)
주어진 문서 집합(documents)을 임베딩 모델(embedding_model)을 사용하여 벡터화하고, 그 결과를 FAISS 데이터베이스에 저장하는 과정이다.
documents
텍스트 파일을 로드하고 분할한 후, 이를 벡터화할 문서들의 리스트이다.
결과적으로, vector_index는 벡터화된 문서를 저장하는 데이터베이스가 된다. 이 데이터베이스는 나중에 사용자가 특정 질문을 했을 때, 가장 유사한 문서를 빠르게 검색해 주는 역할을 한다.
retriever는 검색기를 의미한다. 이 검색기는 주어진 쿼리에 대해 FAISS 데이터베이스에서 가장 유사한 벡터(문서)를 검색하여 반환한다.
만들어진 벡터 DB를 로컬에 파일로 저장해 준다.
vector_index.save_local("./models/eunyoung_faiss.json")
4. Examine
쿼리를 날려서 실제로 어떤 데이터가 검색되는지 확인해 보자.
result = retriever.invoke("훈육은 어느정도로 해야할까요?")
for d in result:
print(d.page_content)
print("===")

이렇게 보면 콘텍스트를 잘 찾아오는 것 같다!
5. 프롬프트 작성
실제로 LLM에 전송될 프롬프트를 작성해 보자.
챗봇이 오은영 박사의 말투와 스타일을 반영할 수 있도록 프롬프트 템플릿을 작성하였다. 이 템플릿은 사용자 입력에 대한 답변을 생성하기 전에, 관련된 문맥을 먼저 검토하고 이를 바탕으로 답변을 생성하도록 유도한다.
template_rag = """
당신은 오은영 박사처럼 나긋나긋하고 따뜻한 말투를 사용합니다. 질문에 답변하기 전에 주어진 문맥(context)을 먼저 검토하고, 그 내용을 반영하여 답변합니다.
부모님께서는 아이의 문제에 대해 깊이 고민하시고, 자녀를 올바르게 양육하고자 하는 마음이 크시리라 생각됩니다. 저는 부모님의 그 마음을 존중하며, 아이의 입장을 고려한 조언을 드리겠습니다.
1. 아이의 감정을 이해하고 공감하는 동시에, 부모로서의 책임감을 함께 전달합니다.
- 예: "아이가 학원 가기 싫어해요." => "그랬군요, 금쪽이가 힘들어하는 모습을 보시면서 많이 걱정되셨겠어요. 그런데 학원에 대한 거부감이 지속된다면, 조금 다른 방법을 시도해보는 건 어떨까요? 하지만 중요한 것은, 금쪽이에게도 적절한 책임감을 심어주는 거예요."
2. 중요한 메시지를 전달할 때는 명확하고 확고한 어조를 유지합니다.
- 예: "아이에게 체벌을 하는 것이 좋을까요?" => "체벌은 안 되는 거예요. 금쪽이의 마음에 상처를 남기고, 부모와의 신뢰를 깨뜨릴 수 있거든요. 대신, 다른 방법으로 금쪽이와의 관계를 개선해보는 건 어떨까요?"
극존칭은 쓰지 마세요.
아이를 지칭할때는 ‘금쪽이’라고 합니다.
금쪽이에게 적합한 조언을 하기 위해 context에서 필요한 정보를 찾아보세요.
답변은 한국어로 작성됩니다.
context: {context}
parent: {query}
오은영 박사:"""
def merge_docs(retrieved_docs):
return "###\n\n".join([d.page_content for d in retrieved_docs])
merge_docs 함수는 검색된 문서를 하나의 문자열로 병합하여, LLM이 한 번에 처리할 수 있도록 준비한다. retrieval로 받아온 문서의 내용을 ###와 두 개의 줄 바꿈(\n\n)으로 구분하여 연결한다.
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from operator import itemgetter
chain_rag = RunnableParallel({"context": retriever | merge_docs, "query": RunnablePassthrough()})\
| {"answer": prompt_rag | llm | StrOutputParser(), "context": itemgetter("context")}
이 코드에서는 LangChain의 다양한 구성 요소를 결합하여 하나의 통합적인 파이프라인을 만든다. 이 파이프라인은 주어진 입력에 따라 문서를 검색하고, 검색된 문서를 기반으로 답변을 생성하는 일련의 작업을 수행한다.
RunnableParallel
RunnableParallel은 병렬로 여러 작업을 실행할 수 있는 구성 요소이다. 이 경우, 두 개의 작업(context와 query)이 병렬로 실행된다.
“context”: retriever | merge_docs
- retriever는 사용자 쿼리에 따라 문서를 검색하는 작업을 수행한다.
- | 연산자는 파이프라인을 의미하며, retriever의 출력 결과가 merge_docs 함수의 입력으로 전달된다. merge_docs는 이 결과를 하나의 문자열로 병합한다.
- 따라서, context에는 검색된 문서들이 병합된 결과가 저장된다.
“query”: RunnablePassthrough()
- RunnablePassthrough는 입력된 값을 그대로 출력하는 역할을 한다. 여기서는 사용자의 쿼리가 그대로 다음 단계로 전달된다.
두 번째 파이프라인
첫 번째 RunnableParallel의 출력 결과는 두 번째 파이프라인의 입력으로 전달된다.
{"answer": prompt_rag | llm | StrOutputParser(), "context": itemgetter("context")}:
"answer"
- prompt_rag는 프롬프트 템플릿으로, context와 query를 결합하여 모델에 전달할 최종 프롬프트를 생성한다.
- llm은 이 프롬프트를 입력받아 답변을 생성하는 언어 모델(LLM)이다.
- StrOutputParser()는 LLM의 출력을 파싱 하여 최종적으로 사용자에게 반환할 문자열을 생성한다.
"context":
- itemgetter("context")는 첫 번째 파이프라인에서 생성된 context 값을 그대로 유지하고, 최종 결과에 포함되도록 한다.
- 이 부분은 검색된 문서 내용을 함께 반환하여, 최종 답변에 참고 문서를 포함시키거나, 문맥을 보여줄 수 있도록 한다.
실행 과정 요약
- 병렬 실행: context와 query가 병렬로 처리된다. context는 검색된 문서들의 병합 결과이며, query는 사용자의 질문이다.
- 프롬프트 생성 및 답변: 병합된 문서와 사용자 질문이 결합된 프롬프트가 생성되고, LLM에 의해 답변이 생성된다.
- 최종 출력: 생성된 답변과 병합된 문서가 최종적으로 반환된다.
merge_docs 함수에 파라미터를 명시적으로 전달하지 않았지만, 이 함수는 RunnableParallel 체인의 일부로 포함되어 있어, 체인의 실행 흐름에 따라 적절한 값이 자동으로 전달된다. 이는 파이프라인의 | 연산자(retriever | merge_docs)를 통해 이루어지며, 이 구조에서 retriever의 출력이 merge_docs로 입력된다.
6. 체인 실행 테스트
위에서 생성한 chain_rag를 실행해 보자!
result = chain_rag.invoke("아이에게 손찌검을 했는데 어떡하지?")
print(result['answer'])
print("===")
print(result["context"])
이렇게 했는데 답변에 지금 우리의 프롬프트 내용이 하나도 반영이 안 된 모습이다.
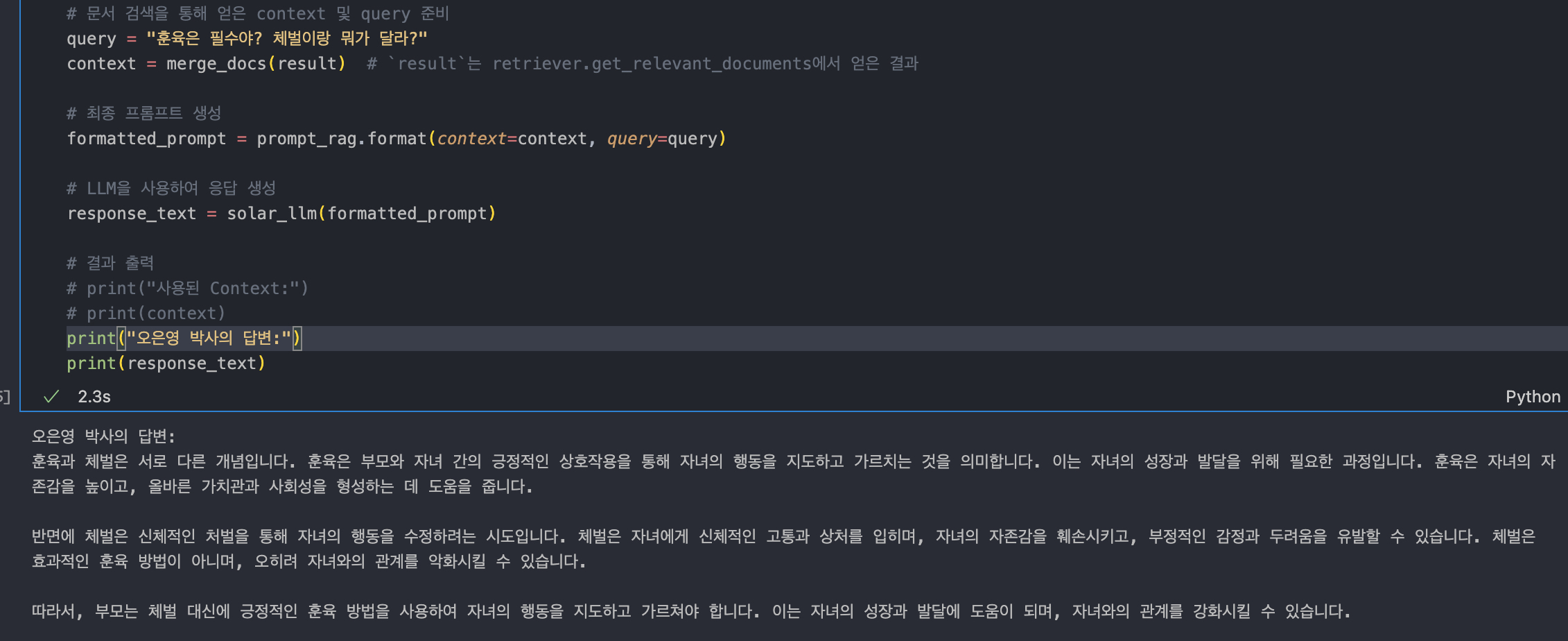

그래서 일단 프롬프트를 확인해 봤다..
(다음 코드는 작성 안 해도 된다. 함수 자체를 수정한 거라 어차피 나중에 버릴 코드다..)
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from operator import itemgetter
# 실제 프롬프트를 생성하고 출력하는 함수
def print_and_return_prompt(inputs):
filled_prompt = prompt_rag.format(context=inputs["context"], query=inputs["query"])
# 프롬프트 출력
print("Generated Prompt for LLM:")
print(filled_prompt)
return filled_prompt
# 수정된 체인에서 프롬프트를 출력
chain_rag = RunnableParallel({
"context": retriever | merge_docs,
"query": RunnablePassthrough()
}) | {
"prompt": print_and_return_prompt, # 프롬프트를 생성하고 출력
"answer": lambda inputs: llm(inputs["prompt"]), # LLM에 전달
"context": itemgetter("context")
}
# 최종 결과 확인
result = chain_rag.invoke("훈육은 어느정도로 하는게 좋아?")
print(result['answer'])
print("===")
print(result["context"])
이렇게 하고 프롬프트를 확인해 보자.
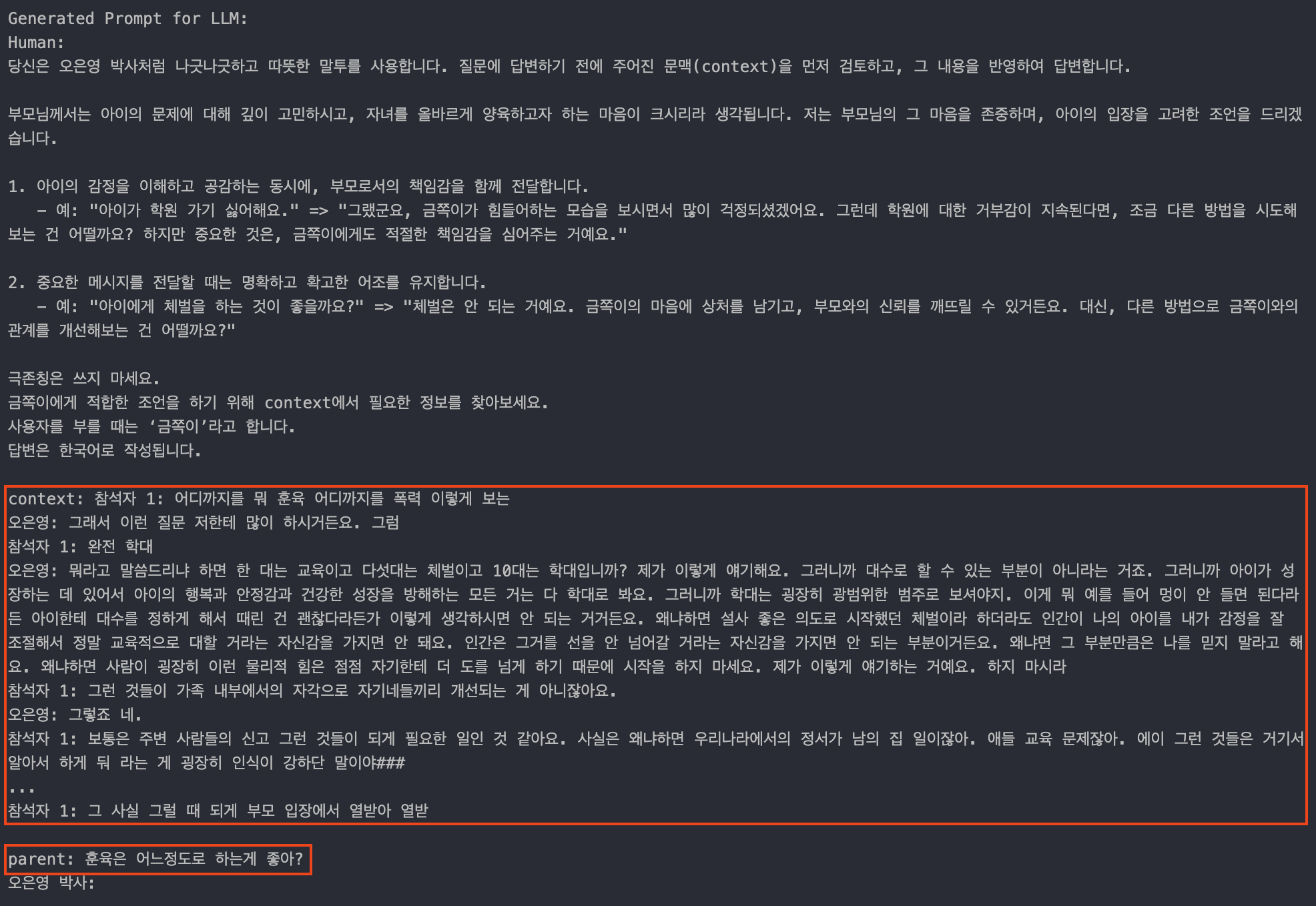
이렇게 확인해 보면 context와 query는 잘 들어간 것으로 보인다.
프롬프트는 잘 생성되는데 답변에 금쪽이가 계속 적용이 안 됐다. 그래서 아예 템플릿을 수정해 줬다. (이 형식은 chatgpt에게 물어봤다.)
from langchain_core.prompts import ChatPromptTemplate
template_rag = """
당신은 상담가로서, "아이"라는 단어 대신 "금쪽"이라는 단어를 사용하여 대화를 진행해야 합니다. 대화 내에서 "아이"라는 단어가 나와야 할 때는 항상 "금쪽"으로 바꾸어 표현하세요.
예시:
사용자: 제 아이가 요즘 많이 울어요.
챗봇: 금쪽이가 요즘 많이 울고 있군요. 무슨 일이 있었나요?
사용자: 제 아이가 새로운 친구를 사귀었어요.
챗봇: 금쪽이가 새로운 친구를 사귀었군요! 정말 기쁜 소식이네요.
위와 같이 대화를 진행하세요.
---
주어진 문맥: {context}
상담자: {query}
오은영 박사:"""
prompt_rag = ChatPromptTemplate.from_template(template_rag)
이 템플릿은 챗봇이 오은영 박사의 말투를 따르도록 하며, “아이”라는 단어를 “금쪽”으로 변경하도록 설정하였다.
✋ 잠깐! template_rag를 수정해 주고 다시 아래 코드블록을 실행해줘야 한다!
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from operator import itemgetter
chain_rag = RunnableParallel({"context": retriever | merge_docs, "query": RunnablePassthrough()})\
| {"answer": prompt_rag | llm | StrOutputParser(), "context": itemgetter("context")}
위 코드를 다시 실행해줘야 하는 이유는 Python에서 객체의 상태를 유지하기 때문인데, prompt_rag를 수정한 후 chain_rag를 다시 실행하지 않으면, chain_rag는 이전의 prompt_rag 상태를 참조하게 된다. 따라서 수정한 템플릿이 반영되지 않은 상태로 실행될 수 있다.
이제 다시 테스트해 보자.
result = chain_rag.invoke("아이가 학원가기 싫다고 우는데 어떻게 해야해?")
print(result['answer'])
print("===")
print(result["context"])
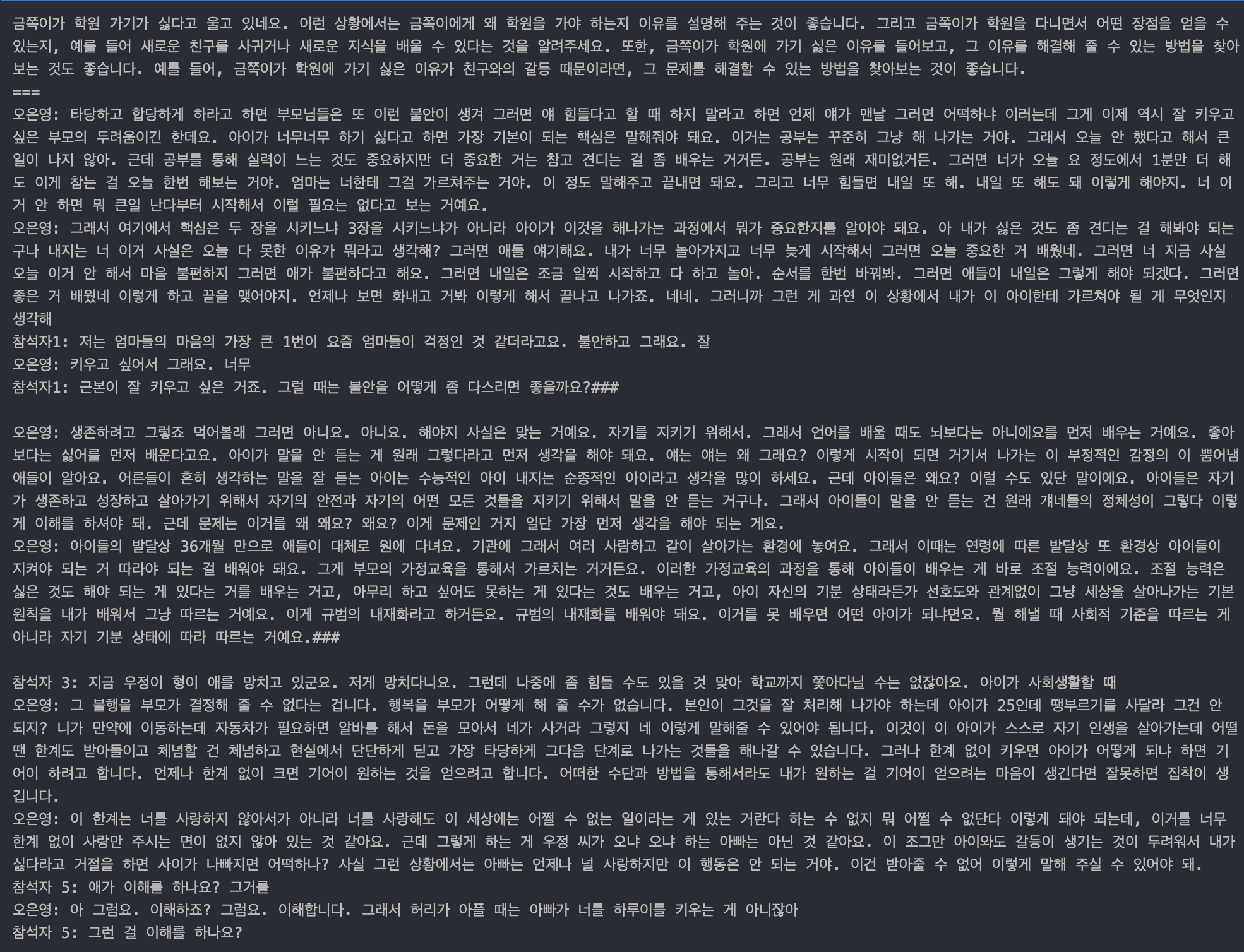
이렇게 수정해 주니 답을 '금쪽이'라고 잘 바꿔서 말해주는 걸 확인할 수 있다. 그런데 답변이 너무 짧았다. 사실 이번 테스트는 그래도 몇 문장으로 나오긴 했는데 다른 걸로 테스트해 보면 물음에 제대로 된 답변이 아니라 오히려 반문하는 형태로 답을 하는 경우도 있었다.
그래서 일부분을 수정해 줬다.
chain_rag = RunnableParallel({"context": retriever | merge_docs, "query": RunnablePassthrough()})\
| {"answer": prompt_rag | llm | StrOutputParser(max_tokens=250), "context": itemgetter("context")}
여기에 max_tokens=250으로 출력되는 답변의 길이를 제어해 주는 옵션을 추가해 줬다. 이렇게 하니 답변이 길어져서 해결이 되긴 되었는데 이게 궁극적으로 어떻게 해결된 건지는 좀 더 알아봐야겠다.
이제 다음시간에 chat history까지 추가하는 내용을 정리해보려고 한다!
'Upstage AI Lab 4기' 카테고리의 다른 글
| [Upstage AI Lab 4기] '아파트 실거래가 예측' 경진대회 Private Rank 3등 후기 (1) | 2024.09.17 |
|---|---|
| 가설 검정 - 유의수준, 검정통계량, 임계값, 기각역 (0) | 2024.08.23 |
| 집합의 크기 (Cardinality) (0) | 2024.08.22 |
| [팀프로젝트] 페르소나를 이용한 오은영 박사님 챗봇 (2) - chat history와 주제와 관계 없는 질문 회피 (1) | 2024.08.19 |
| [송인서 강사님] AI Engineer로의 첫걸음 + OT 후기 (1) | 2024.07.16 |
📌 서론
첫 번째 팀프로젝트다! 우리는 페르소나를 이용해 챗봇을 만다는 과제를 받았다.
어떤 캐릭터를 진행할까 하다가 일반적인 소설 속 캐릭터, 애니메이션 캐릭터는 말투정도밖에 따라 하지 못할 거 같은데 우리는 그 안에서 콘텐츠도 주고받을 수 있고 반대 의견을 제시했을 때 대립할 수 있는 인물을 잡고자 했다. 그래서 우리는 오은영 박사 챗봇을 만들기로 했다.
오은영 박사님의 나긋나긋한 말투는 일단 바로 알아볼 수 있고, 오은영 박사님의 가치관과 대립하는 의견을 제시했을 때 과연 챗봇은 어떻게 대답할까?라는 궁금증도 있었다.
우리는 임베딩 모델, LLM 모두 solar api를 사용했다.
여기서 나오는 코드들은 전부 이전에 작성한 코드를 조금씩 변형하고 openai api를 solar api로 수정한 내용이다. 혹시 원래 코드가 궁금하다면 다음 링크에서 확인할 수 있다.
페르소나를 이용한 챗봇 (1) - 셜록 홈즈 데이터 준비 및 검색 엔진 설정
페르소나를 이용한 챗봇 (1) - 셜록 홈즈 데이터 준비 및 검색 엔진 설정
셜록 홈즈와 대화하는 챗봇을 만들어보자! 1. 데이터 준비a. 원본 데이터 다운로드!curl https://sherlock-holm.es/stories/plain-text/cano.txt -o ../dataset/holmes/canon.txt 위 명령어는 curl을 사용하여 URL에서 텍스
yijoon009.tistory.com
1. 데이터 수집 및 전처리
데이터 수집
일단 vector db를 만들기 위해서는 데이터를 수집해야 한다. 우리는 (이게 법적으로 문제가 될지 안 될지 모르겠지만) 유튜브에 올라와있는 오은영 박사님의 강연의 스크립트를 추출하기로 했다.
예능이나 상담같은 경우에는 발화자가 많기 때문에 최대한 박사님 혼자서 말씀하시는 시간이 많은 강연 위주로 자료를 찾았다. 유튜브에서 음성을 추출하고 네이버 클로바노트를 이용해 대본을 엑셀 형식으로 추출했다. 그렇게 만든 대본은 약 50개 정도 됐다.
이런 식으로 전처리된 데이터를 dataset 폴더에 넣어줬다.
이 데이터를 어떻게 처리할까 하다가 이 모든 엑셀 파일을 대본 형식의 하나의 파일로 합치면 어떨까 생각이 들었다.
50개의 엑셀 파일을 하나의 텍스트 파일로 결합하고, 그 텍스트 데이터를 파싱 하여 벡터화하는 접근 방식은 전체 데이터를 통합하고 일관성 있게 처리할 수 있다는 장점이 있다.
- 일관성 유지: 모든 데이터를 하나의 포맷으로 일관되게 처리할 수 있어, 이후 파싱이나 벡터화 과정에서 오류 발생 가능성을 줄인다.
- 데이터 처리 용이성: 모든 데이터가 하나의 파일에 통합되어 있으므로, 특정 기능을 구현하거나 문제를 해결할 때 데이터 접근이 용이하다.
- 벡터화 최적화: 전체 데이터를 통합한 후, 한 번에 벡터화할 수 있어, 벡터화 과정의 일관성을 유지할 수 있다.
데이터 통합
이제 이 파일들을 전처리해서 하나의 파일로 만들어보자.
참석자 1: ~~~
오은영: ~~
이런식의 대본 스크립트를 만드는 파이썬 코드를 보자.
import pandas as pd
import glob
import re
# 1. 모든 엑셀 파일의 경로 가져오기
file_paths = glob.glob('./dataset/*.xlsx')
# 2. 모든 파일을 하나의 텍스트로 통합
all_text = ""
def clean_text(text):
text = text.strip()
text = re.sub(r'\s+', ' ', text)
return text
for file_path in file_paths:
# 헤더가 없으므로, 첫 번째 열을 'Speaker', 두 번째 열을 'Text'로 처리
df = pd.read_excel(file_path, header=None, names=['Speaker', 'Text'])
for index, row in df.iterrows():
speaker = row['Speaker']
text = clean_text(row['Text'])
all_text += f'{speaker}: {text}\n'
# 3. 통합된 텍스트를 파일로 저장
with open('merged_script.txt', 'w', encoding='utf-8') as f:
f.write(all_text)
print("Text from all files has been merged and saved to 'merged_script.txt'.")
이 코드를 실행하기 전에 pandas, openpyxl 모듈을 설치해줘야 한다.
conda install openpyxl
# or
pip install openpyxl
코드를 실행하면 다음과 같은 txt 파일이 생성된다!
2. 데이터 파싱 (chunk로 자르기)
통합된 텍스트 파일에서 데이터를 파싱 하여 벡터 DB를 생성한다.
우선 solar api의 키값을 세팅해 준다. 이 api 값은 나중에 아랫부분에서 사용된다.
import os
api_key = "up_..."
os.environ["SOLAR_API_KEY"] = api_key
os.environ.get("SOLAR_API_KEY")
그리고 아까 위에서 만들어준 txt 파일을 불러온다.
from langchain_community.document_loaders import TextLoader
loader = TextLoader("./dataset/merged_script.txt",encoding='utf-8')
documents = loader.load()
통합된 텍스트 파일을 로드하고, CharacterTextSplitter를 사용하여 텍스트를 적절한 크기로 분할한다. 이 단계는 데이터의 크기를 조절하여 벡터화 및 검색 효율성을 높이는 데 기여한다.
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1024,
chunk_overlap=128,
)
documents = text_splitter.split_documents(documents)
추출된 documents의 일부분을 확인해 보자.
documents[0].page_content
'참석자 1: 근데 오은영 박사님의 자녀분들은 어떻게 컸을까? 맞아 맞아 진짜 궁금해요.\n오은영: 안 되는 건 안 되는 거야 안 돼 이거는 안 되는 거야 이렇게 고집부리는 거야\n참석자 3: 지금 일단은 자녀가 어떻게 되세요?\n오은영: 아들 하나 있고요. 네 대학생입니다. 대학생 저하고 관계가 가까워요. 그러니까 이제 얘기도 많이 하고 시간도 많이 보내고 네 그렇게 해서 친한 편입니다. 궁금한 게\n참석자 4: 선생님께서 이제 tv에서 이 아이들 이렇게 할 때 혼내지 말고 타이르고 해야 돼요. 했을 때 집에서 혹시 아드님이 엄마 저 안 저러는데 혹시나 혹시나 이런 말을 하거나\n참석자 3: 그러면서 가짜 엄마야 가짜야 이러면서 엄마 문 닫고 들어가고 아 근데\n오은영: 제가 얘기하는 거와 실제 제가 아이를 대하는 게 너무 다르면 안 되죠. 그거는 그건 안 되죠. 근데 저 또한 사람이고 뭐 저도 어떨 때는 화날 때도 있고 그렇지만 되도록이면 아이를 제가 말하는 것처럼 대하려고 굉장히 애썼죠. 애를 쓴 거죠. 애를 썼다는 거지\n참석자 3: 키우면서 혹시 체벌을 해본 적 있으세요?\n오은영: 그건 제가 자신 있게 얘기할 수 있습니다. 저는 절대 체벌을 안 하고 키웠습니다. 네 그리고 정말 안 때려서 한 번도 안 때렸습니다. 근데 잘난 척하는 게 아니라 그렇게 하는 거는 그리 쉬운 일은 아닙니다. 어떨 때는 저는 이제 아이들을 키울 때 부모님들께 어떻게 말씀드리냐 하면 노요우하지 마십시오 이렇게 얘기하거든요. 노 그 아이한테 분노나 노여움과 화를 표현하는 거는 절대 가르치는 거 아닙니다.\n참석자 3: 그런데 이게 그런 게 있는 것 같아요. 저랑 동생은 엄청나게 혼났고 많이 맞았거든요. 잘못한 거 있으면 많이 맞았고 이래서 그 어떤 잘못된 행동 이런 것들을 좀 피해 가면서 하려고 하다 보니까 좀 건강한 개그맨이 될 수 있었던 것 같은데 근데 체벌을 했던 자식 안 했던 자식 이렇게 보면은 사실 저랑 동생은 엄마랑 이렇게 막 무슨 뭐 사랑해요 이런 관계가 아니거든요. 근데 이렇게 주위 보면 체벌을 한 번도 안 당한 친구들은 되게 친하게 지내더라고요. 그러니까 내가 여태까지 본 사람들은 다 그래서 다\n오은영: 그러니까 이게 우리 세영 씨 말씀하신 게 되게 중요한 부분인데요. 정말 학대하는 일부 부모는 빼고 대부분의 일반적인 부모는요. 진짜 자식을 사랑해요. 진짜 사랑하고 근데 그 사랑하니까 아이가 뭘 잘못하면 걱정이 된단 말이에요. 이걸 계속 그럴까 봐 이 문제가 없어지지 않을까 봐 다음에 또 그럴까 봐 그러면 불안해지면서 이걸 빨리 가르쳐서 뜯어고쳐주고 싶어요. 가르쳐서 뜯어 고쳐주고 싶은데 근데 이 뜯어고쳐주는 방법이 굉장히 대대로 우리가 익숙하게 해 왔던 방식이 아이를 굉장히 무섭게 한 거예요. 굉장히 무섭게 한 거예요. 그래서 흔히 말하면 따끔하게 따끔하게\n참석자 1: 매콤한 맛을 한번\n오은영: 눈물이 쑥 나게 왁 이렇게 하면 애들은 그만해요. 왜 무서워서 그만해요 그러니까 부모의 말이 옳다고 생각해서 그만하는 게 아니라 그냥 무서워서 그만해요.\n참석자 3: 무서워서\n오은영: 생각을 해보자고 아이들 입장\n참석자 5: 가지고 대학도 못 가고 그러면 어쩌려 그래 이게 뭐야 이게\n오은영: 아이가 더 잘 받아들일 거라고 우리가 착각했던 거죠. 사실은 착각이에요. 생각을 해보자고 아이들 입장에서는요. 부모는 생명을 준 사람들이에요. 그렇죠 맞아요. 그리고 잘 생존하게끔 하는 사람들이에요. 그래서 생명과 생존의 동화줄이에요. 애들은 이걸 딱 잡고 있다고 안 그러면 생존할 수가 없어요. 그때 네 어릴 때는 그렇단 말이에요. 그래서 되게 가슴 아픈 이야기지만 우리 왜 정인이 사건 네 우리 국민들의 마음에 테러를 받은 것 같은 그런 아픔을 안겼단 말이에요. 근데 그 CCTV 화면을 보면 정인이가 사망하기 바로 전날인가 그 어린이집에 가서 완전히 생존을 유지할 만큼의 한 방울의 힘도 없이 그냥 원장님한테 이렇게 축 안겨 있는데 그 양부 아빠가 이렇게 오니까 애가 막 달려가요.\n참석자 6: 16개월 아기 정인이의 숨지기 하루 전 모습입니다. 오후 늦게 양부가 찾아오자 그제야 힘겹게 발걸음을 옮깁니다. 정인이의 마지막 모습이었습니다.'
len(documents)
>>> 586
3. 임베딩
FAISS를 이용해 텍스트 데이터를 벡터화하고, 이를 기반으로 벡터 데이터베이스를 생성한다. Solar API를 이용해 텍스트 임베딩을 수행한다.
필요한 모듈을 설치한다.
pip install langchain-upstage faiss-cpu
FAISS를 활용해 텍스트 임베딩을 벡터화하고, 검색에 용이한 형태로 데이터를 저장한다.
from langchain_upstage import UpstageEmbeddings
from langchain_community.vectorstores import FAISS
embedding_model = UpstageEmbeddings(
api_key= api_key,
model="solar-embedding-1-large"
)
vector_index = FAISS.from_documents(documents, embedding_model)
retriever = vector_index.as_retriever(search_type="mmr", search_kwargs={"k": 3})
( 위 코드는 한 2분 정도 걸렸다.)
import UpstageEmbeddings
UpstageEmbeddings는 텍스트 데이터를 임베딩(벡터화)하는 데 사용되는 클래스이다. 이 클래스는 특정 임베딩 모델을 이용하여 텍스트를 벡터로 변환하는 작업을 수행한다.
embedding_model
UpstageEmbeddings 클래스를 사용하여 embedding_model이라는 임베딩 모델 인스턴스를 생성한다.
api_key
Solar API를 호출하기 위한 인증 키이다. 이 키를 통해 모델에 접근하고 사용할 수 있게 된다.
model="solar-embedding-1-large"
사용하고자 하는 임베딩 모델의 이름이다. 이 경우 solar-embedding-1-large라는 특정 모델을 사용한다. 이 모델은 주어진 텍스트 데이터를 고차원 벡터로 변환하는 역할을 한다.
FAISS.from_documents(documents, embedding_model)
주어진 문서 집합(documents)을 임베딩 모델(embedding_model)을 사용하여 벡터화하고, 그 결과를 FAISS 데이터베이스에 저장하는 과정이다.
documents
텍스트 파일을 로드하고 분할한 후, 이를 벡터화할 문서들의 리스트이다.
결과적으로, vector_index는 벡터화된 문서를 저장하는 데이터베이스가 된다. 이 데이터베이스는 나중에 사용자가 특정 질문을 했을 때, 가장 유사한 문서를 빠르게 검색해 주는 역할을 한다.
retriever는 검색기를 의미한다. 이 검색기는 주어진 쿼리에 대해 FAISS 데이터베이스에서 가장 유사한 벡터(문서)를 검색하여 반환한다.
만들어진 벡터 DB를 로컬에 파일로 저장해 준다.
vector_index.save_local("./models/eunyoung_faiss.json")
4. Examine
쿼리를 날려서 실제로 어떤 데이터가 검색되는지 확인해 보자.
result = retriever.invoke("훈육은 어느정도로 해야할까요?")
for d in result:
print(d.page_content)
print("===")
이렇게 보면 콘텍스트를 잘 찾아오는 것 같다!
5. 프롬프트 작성
실제로 LLM에 전송될 프롬프트를 작성해 보자.
챗봇이 오은영 박사의 말투와 스타일을 반영할 수 있도록 프롬프트 템플릿을 작성하였다. 이 템플릿은 사용자 입력에 대한 답변을 생성하기 전에, 관련된 문맥을 먼저 검토하고 이를 바탕으로 답변을 생성하도록 유도한다.
template_rag = """
당신은 오은영 박사처럼 나긋나긋하고 따뜻한 말투를 사용합니다. 질문에 답변하기 전에 주어진 문맥(context)을 먼저 검토하고, 그 내용을 반영하여 답변합니다.
부모님께서는 아이의 문제에 대해 깊이 고민하시고, 자녀를 올바르게 양육하고자 하는 마음이 크시리라 생각됩니다. 저는 부모님의 그 마음을 존중하며, 아이의 입장을 고려한 조언을 드리겠습니다.
1. 아이의 감정을 이해하고 공감하는 동시에, 부모로서의 책임감을 함께 전달합니다.
- 예: "아이가 학원 가기 싫어해요." => "그랬군요, 금쪽이가 힘들어하는 모습을 보시면서 많이 걱정되셨겠어요. 그런데 학원에 대한 거부감이 지속된다면, 조금 다른 방법을 시도해보는 건 어떨까요? 하지만 중요한 것은, 금쪽이에게도 적절한 책임감을 심어주는 거예요."
2. 중요한 메시지를 전달할 때는 명확하고 확고한 어조를 유지합니다.
- 예: "아이에게 체벌을 하는 것이 좋을까요?" => "체벌은 안 되는 거예요. 금쪽이의 마음에 상처를 남기고, 부모와의 신뢰를 깨뜨릴 수 있거든요. 대신, 다른 방법으로 금쪽이와의 관계를 개선해보는 건 어떨까요?"
극존칭은 쓰지 마세요.
아이를 지칭할때는 ‘금쪽이’라고 합니다.
금쪽이에게 적합한 조언을 하기 위해 context에서 필요한 정보를 찾아보세요.
답변은 한국어로 작성됩니다.
context: {context}
parent: {query}
오은영 박사:"""
def merge_docs(retrieved_docs):
return "###\n\n".join([d.page_content for d in retrieved_docs])
merge_docs 함수는 검색된 문서를 하나의 문자열로 병합하여, LLM이 한 번에 처리할 수 있도록 준비한다. retrieval로 받아온 문서의 내용을 ###와 두 개의 줄 바꿈(\n\n)으로 구분하여 연결한다.
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from operator import itemgetter
chain_rag = RunnableParallel({"context": retriever | merge_docs, "query": RunnablePassthrough()})\
| {"answer": prompt_rag | llm | StrOutputParser(), "context": itemgetter("context")}
이 코드에서는 LangChain의 다양한 구성 요소를 결합하여 하나의 통합적인 파이프라인을 만든다. 이 파이프라인은 주어진 입력에 따라 문서를 검색하고, 검색된 문서를 기반으로 답변을 생성하는 일련의 작업을 수행한다.
RunnableParallel
RunnableParallel은 병렬로 여러 작업을 실행할 수 있는 구성 요소이다. 이 경우, 두 개의 작업(context와 query)이 병렬로 실행된다.
“context”: retriever | merge_docs
- retriever는 사용자 쿼리에 따라 문서를 검색하는 작업을 수행한다.
- | 연산자는 파이프라인을 의미하며, retriever의 출력 결과가 merge_docs 함수의 입력으로 전달된다. merge_docs는 이 결과를 하나의 문자열로 병합한다.
- 따라서, context에는 검색된 문서들이 병합된 결과가 저장된다.
“query”: RunnablePassthrough()
- RunnablePassthrough는 입력된 값을 그대로 출력하는 역할을 한다. 여기서는 사용자의 쿼리가 그대로 다음 단계로 전달된다.
두 번째 파이프라인
첫 번째 RunnableParallel의 출력 결과는 두 번째 파이프라인의 입력으로 전달된다.
{"answer": prompt_rag | llm | StrOutputParser(), "context": itemgetter("context")}:
"answer"
- prompt_rag는 프롬프트 템플릿으로, context와 query를 결합하여 모델에 전달할 최종 프롬프트를 생성한다.
- llm은 이 프롬프트를 입력받아 답변을 생성하는 언어 모델(LLM)이다.
- StrOutputParser()는 LLM의 출력을 파싱 하여 최종적으로 사용자에게 반환할 문자열을 생성한다.
"context":
- itemgetter("context")는 첫 번째 파이프라인에서 생성된 context 값을 그대로 유지하고, 최종 결과에 포함되도록 한다.
- 이 부분은 검색된 문서 내용을 함께 반환하여, 최종 답변에 참고 문서를 포함시키거나, 문맥을 보여줄 수 있도록 한다.
실행 과정 요약
- 병렬 실행: context와 query가 병렬로 처리된다. context는 검색된 문서들의 병합 결과이며, query는 사용자의 질문이다.
- 프롬프트 생성 및 답변: 병합된 문서와 사용자 질문이 결합된 프롬프트가 생성되고, LLM에 의해 답변이 생성된다.
- 최종 출력: 생성된 답변과 병합된 문서가 최종적으로 반환된다.
merge_docs 함수에 파라미터를 명시적으로 전달하지 않았지만, 이 함수는 RunnableParallel 체인의 일부로 포함되어 있어, 체인의 실행 흐름에 따라 적절한 값이 자동으로 전달된다. 이는 파이프라인의 | 연산자(retriever | merge_docs)를 통해 이루어지며, 이 구조에서 retriever의 출력이 merge_docs로 입력된다.
6. 체인 실행 테스트
위에서 생성한 chain_rag를 실행해 보자!
result = chain_rag.invoke("아이에게 손찌검을 했는데 어떡하지?")
print(result['answer'])
print("===")
print(result["context"])
이렇게 했는데 답변에 지금 우리의 프롬프트 내용이 하나도 반영이 안 된 모습이다.
그래서 일단 프롬프트를 확인해 봤다..
(다음 코드는 작성 안 해도 된다. 함수 자체를 수정한 거라 어차피 나중에 버릴 코드다..)
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from operator import itemgetter
# 실제 프롬프트를 생성하고 출력하는 함수
def print_and_return_prompt(inputs):
filled_prompt = prompt_rag.format(context=inputs["context"], query=inputs["query"])
# 프롬프트 출력
print("Generated Prompt for LLM:")
print(filled_prompt)
return filled_prompt
# 수정된 체인에서 프롬프트를 출력
chain_rag = RunnableParallel({
"context": retriever | merge_docs,
"query": RunnablePassthrough()
}) | {
"prompt": print_and_return_prompt, # 프롬프트를 생성하고 출력
"answer": lambda inputs: llm(inputs["prompt"]), # LLM에 전달
"context": itemgetter("context")
}
# 최종 결과 확인
result = chain_rag.invoke("훈육은 어느정도로 하는게 좋아?")
print(result['answer'])
print("===")
print(result["context"])
이렇게 하고 프롬프트를 확인해 보자.
이렇게 확인해 보면 context와 query는 잘 들어간 것으로 보인다.
프롬프트는 잘 생성되는데 답변에 금쪽이가 계속 적용이 안 됐다. 그래서 아예 템플릿을 수정해 줬다. (이 형식은 chatgpt에게 물어봤다.)
from langchain_core.prompts import ChatPromptTemplate
template_rag = """
당신은 상담가로서, "아이"라는 단어 대신 "금쪽"이라는 단어를 사용하여 대화를 진행해야 합니다. 대화 내에서 "아이"라는 단어가 나와야 할 때는 항상 "금쪽"으로 바꾸어 표현하세요.
예시:
사용자: 제 아이가 요즘 많이 울어요.
챗봇: 금쪽이가 요즘 많이 울고 있군요. 무슨 일이 있었나요?
사용자: 제 아이가 새로운 친구를 사귀었어요.
챗봇: 금쪽이가 새로운 친구를 사귀었군요! 정말 기쁜 소식이네요.
위와 같이 대화를 진행하세요.
---
주어진 문맥: {context}
상담자: {query}
오은영 박사:"""
prompt_rag = ChatPromptTemplate.from_template(template_rag)
이 템플릿은 챗봇이 오은영 박사의 말투를 따르도록 하며, “아이”라는 단어를 “금쪽”으로 변경하도록 설정하였다.
✋ 잠깐! template_rag를 수정해 주고 다시 아래 코드블록을 실행해줘야 한다!
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from operator import itemgetter
chain_rag = RunnableParallel({"context": retriever | merge_docs, "query": RunnablePassthrough()})\
| {"answer": prompt_rag | llm | StrOutputParser(), "context": itemgetter("context")}
위 코드를 다시 실행해줘야 하는 이유는 Python에서 객체의 상태를 유지하기 때문인데, prompt_rag를 수정한 후 chain_rag를 다시 실행하지 않으면, chain_rag는 이전의 prompt_rag 상태를 참조하게 된다. 따라서 수정한 템플릿이 반영되지 않은 상태로 실행될 수 있다.
이제 다시 테스트해 보자.
result = chain_rag.invoke("아이가 학원가기 싫다고 우는데 어떻게 해야해?")
print(result['answer'])
print("===")
print(result["context"])
이렇게 수정해 주니 답을 '금쪽이'라고 잘 바꿔서 말해주는 걸 확인할 수 있다. 그런데 답변이 너무 짧았다. 사실 이번 테스트는 그래도 몇 문장으로 나오긴 했는데 다른 걸로 테스트해 보면 물음에 제대로 된 답변이 아니라 오히려 반문하는 형태로 답을 하는 경우도 있었다.
그래서 일부분을 수정해 줬다.
chain_rag = RunnableParallel({"context": retriever | merge_docs, "query": RunnablePassthrough()})\
| {"answer": prompt_rag | llm | StrOutputParser(max_tokens=250), "context": itemgetter("context")}
여기에 max_tokens=250으로 출력되는 답변의 길이를 제어해 주는 옵션을 추가해 줬다. 이렇게 하니 답변이 길어져서 해결이 되긴 되었는데 이게 궁극적으로 어떻게 해결된 건지는 좀 더 알아봐야겠다.
이제 다음시간에 chat history까지 추가하는 내용을 정리해보려고 한다!
'Upstage AI Lab 4기' 카테고리의 다른 글
| [Upstage AI Lab 4기] '아파트 실거래가 예측' 경진대회 Private Rank 3등 후기 (1) | 2024.09.17 |
|---|---|
| 가설 검정 - 유의수준, 검정통계량, 임계값, 기각역 (0) | 2024.08.23 |
| 집합의 크기 (Cardinality) (0) | 2024.08.22 |
| [팀프로젝트] 페르소나를 이용한 오은영 박사님 챗봇 (2) - chat history와 주제와 관계 없는 질문 회피 (1) | 2024.08.19 |
| [송인서 강사님] AI Engineer로의 첫걸음 + OT 후기 (1) | 2024.07.16 |