
nGrinder를 활용한 부하 테스트 - 기본에서 전략까지

📌 서론
이전 글에서 macOS에서 nGrinder를 설치하고 실행하는 과정을 작성했다. 이번 글에서 실제로 부하 테스트를 진행해 보자.
🔻 이전글에서 작성한 테스트 스크립트를 이번 글에서 사용하니 꼭 이전글을 읽고 오길 바란다. 🔻
macOS에서 nGrinder 설치 - 엔그라인더 환경 설정
macOS에서 nGrinder 설치 - 엔그라인더 환경 설정
macOS에서 nGrinder 설치 - 엔그라인더 환경 설정 📌 서론 우리가 진행하던 프로젝트의 베타 버전이 배포되었다. 이제 부하 테스트를 진행하기 위해 nGrinder를 사용해 보기로 했다. 실제로 부하 테스
yijoon009.tistory.com
1. 부하 테스트 생성
나는 일단 가장 기본적으로 JWT 없이 간단하게 할 수 있는 전화번호 중복체크를 테스트해 보기로 했다. (이전 글에서 작성한 테스트 스크립트와 동일하다.)
성능 테스트 메뉴로 이동하자. 화면 제일 상단에 메뉴 버튼이 있다. 그리고 페이지 이동해서 나오는 [테스트 생성] 버튼을 클릭해 준다.
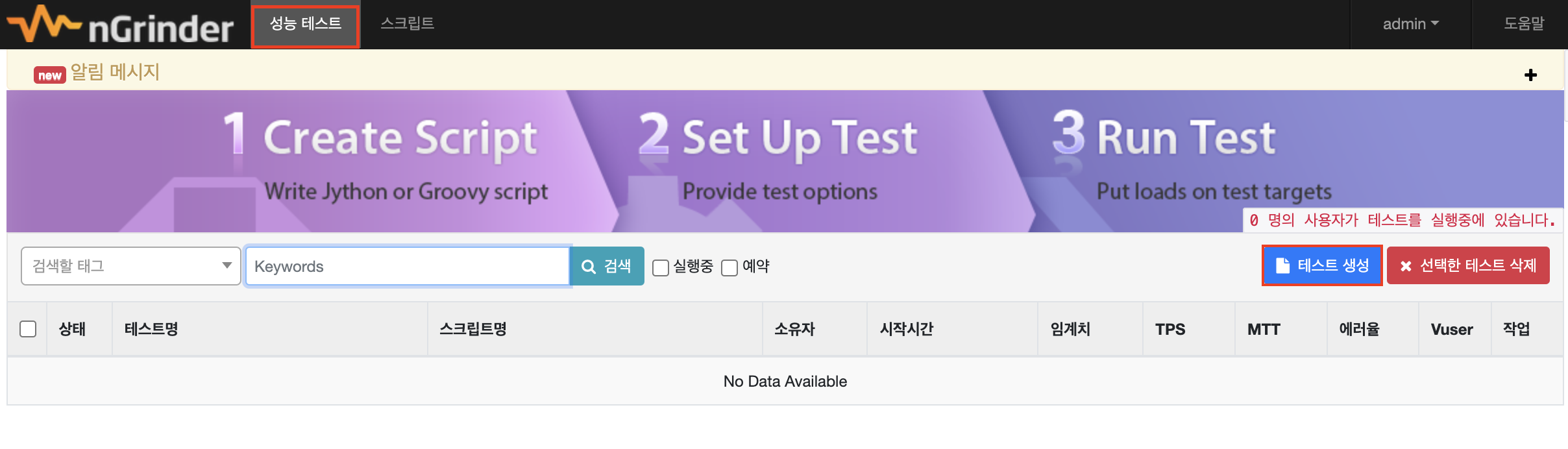
그럼 다음과 같은 화면이 나온다.

각 항목에 대해서 알아보자.
에이전트(Agent)
ngrinder에서 에이전트는 부하 테스트를 실제로 실행하는 역할을 한다. 네트워크를 통해 테스트 컨트롤러와 통신하며, 컨트롤러로부터 받은 스크립트를 실행한다. 에이전트 1개는 테스트를 수행하는 단일 머신을 의미한다.
가상 사용자(VUser)
가상 사용자는 실제 사용자의 행동을 모방하여 시스템에 요청을 보내는 역할을 한다. 가상 사용자 수를 설정함으로써 동시에 시스템에 접근하는 사용자 수를 모의할 수 있다.
프로세스(Process)
프로세스는 가상 사용자들이 실행되는 환경을 말한다. ngrinder에서는 가상 사용자들을 여러 프로세스에 분산시켜 부하를 생성한다. 각 프로세스는 독립된 JVM(Java Virtual Machine)에서 실행된다.
쓰레드(Thread)
쓰레드는 프로세스 내에서 실제로 작업을 수행하는 단위이다. 가상 사용자는 쓰레드로 구현되어, 각 쓰레드가 하나의 가상 사용자의 행동을 담당한다.
nGrinder에서는 프로세스와 쓰레드를 곱한 값으로 동시에 시스템에 접근할 수 있는 가상 사용자(VUser)의 수를 결정한다.
예를 들어, 2개의 프로세스와 각 프로세스 당 50개의 쓰레드를 설정하면, 총 100개의 가상 사용자가 동시에 시스템에 요청을 보내는 것과 같은 효과를 낸다. 이는 다양한 부하 상황을 시뮬레이션하여 시스템의 성능과 용량을 평가하는 데 중요한 역할을 한다.
이러한 요소들은 모두 함께 작동하여 복잡한 사용자 환경을 모방하고, 시스템의 성능을 정밀하게 측정할 수 있게 해 준다. 각 요소는 부하 테스트의 정확성과 효율성을 높이는 데 기여한다.
스크립트(Script)
스크립트는 부하 테스트 시 시스템에 보낼 요청들을 정의한 코드이다. nGrinder에서는 Groovy나 Java로 작성된 스크립트를 사용하여, HTTP 요청, API 호출 등 실제 사용자의 행동을 모방한다. 스크립트는 부하 테스트의 핵심이며, 실제 사용 시나리오에 맞게 정교하게 작성되어야 한다.
웹 브라우저 제일 상단에 [스크립트] 메뉴를 클릭해 그곳에서 스크립트를 작성할 수 있다.
스크립트 리소스(Script Resource)
스크립트 리소스는 스크립트 실행에 필요한 추가 파일이나 데이터를 의미한다. 예를 들어, 사용자 목록, 테스트 데이터 파일 등이 이에 해당한다. 이러한 리소스는 스크립트와 함께 업로드되어 테스트 실행 시 참조될 수 있다.
테스트 대상 서버(Test Target Server)
테스트 대상 서버는 부하 테스트의 대상이 되는 시스템이다. 이 서버는 웹 애플리케이션, API, 또는 다른 네트워크 서비스일 수 있으며, nGrinder는 이 서버에 대해 정의된 스크립트를 실행하여 부하를 생성한다.
테스트 기간(Test Duration)
테스트 기간은 부하 테스트를 실행할 시간을 의미한다. 이 기간 동안 시스템은 지속적으로 요청을 받아 처리한다. 테스트 기간을 설정함으로써, 시스템의 성능을 장기간 관찰하고, 다양한 부하 조건에서의 반응을 측정할 수 있다.
실행 횟수(Execution Count)
실행 횟수는 특정 스크립트를 몇 번 실행할지를 결정하는 설정이다. 이는 테스트의 반복성을 보장하며, 결과의 신뢰성을 높이는 데 도움을 준다. 특히, 변동성이 큰 테스트 결과에 대해 안정적인 데이터를 얻고자 할 때 유용하다.
Ramp-up
Ramp-up은 부하 테스트에서 가상 사용자를 일정한 속도로 점진적으로 증가시키는 방법을 말한다. 이 기능을 사용하면 테스트의 시작 부분에서 전체 부하를 갑자기 적용하는 대신, 설정된 시간 동안 서서히 부하를 증가시켜 시스템에 대한 충격을 줄이고, 시스템이 점진적으로 증가하는 부하에 어떻게 반응하는지 관찰할 수 있다.
Ramp-up 설정 요소
프로세스 및 쓰레드 선택
Ramp-up을 적용할 대상(프로세스 또는 쓰레드)을 선택한다. 여기서는 부하를 생성할 때 프로세스 또는 쓰레드 단위로 증가시킬지 결정한다.
초기 개수(Initial Count)
테스트 시작 시 생성할 프로세스 또는 쓰레드의 초기 수를 의미한다. 예를 들어, 초기 개수를 10으로 설정하면 테스트 시작 시 10개의 프로세스 또는 쓰레드가 생성된다.
증가 단위(Increment)
각 Ramp-up 주기마다 얼마나 많은 프로세스 또는 쓰레드를 추가할지 결정한다. 예를 들어, 증가 단위를 5로 설정하면, 각 주기마다 5개의 프로세스 또는 쓰레드가 추가된다.
초기 대기 시간(Initial Delay)
테스트 시작 후 실제로 Ramp-up을 시작하기까지의 대기 시간을 의미한다. 이 시간 동안은 초기 개수로 설정된 프로세스 또는 쓰레드만이 활성화된다.
Ramp-up 주기(Period)
증가 단위에 따라 프로세스 또는 쓰레드를 얼마나 자주 증가시킬지 결정하는 시간 간격이다. 예를 들어, Ramp-up 주기를 1분으로 설정하면, 매 1분마다 증가 단위만큼 프로세스 또는 쓰레드가 추가된다.
Ramp-up 사용의 이점
Ramp-up 기능을 사용하면 다음과 같은 이점을 얻을 수 있다:
- 성능 저하의 원인 분석: 점진적으로 부하를 증가시키면서 시스템의 성능 저하가 시작되는 지점을 더 정확하게 파악할 수 있다.
- 자원 사용률 모니터링: 시스템의 자원 사용률이 시간에 따라 어떻게 변화하는지 관찰할 수 있어, 자원 병목 현상을 식별하는 데 도움이 된다.
- 시스템 안정성 평가: 시스템이 점진적으로 증가하는 부하에 어떻게 반응하는지 관찰함으로써, 실제 운영 환경에서의 시스템 안정성을 평가할 수 있다.
Ramp-up 설정을 통해 부하 테스트의 유연성을 높이고, 시스템의 성능 한계와 안정성을 보다 정밀하게 평가할 수 있다.
2. 부하 테스트 실행
일단 테스트가 되는지 확인하기 위해 가장 기본적인 설정으로 세팅해 줬다. 그리고 상단에 [저장 후 시작] 버튼을 클릭하면 된다.

내가 작성한 테스트 설정은 다음과 같다.
- 에이전트 1개: 테스트를 실행할 머신이 1대임을 의미한다.
- 가상 사용자 99명: 동시에 99명의 사용자가 시스템을 사용하는 상황을 모의한다.
- 프로세스 3개: 가상 사용자들이 실행될 JVM의 개수를 3개로 설정함을 의미한다.
- 쓰레드 33개: 각 프로세스당 33개의 쓰레드를 생성하여 가상 사용자를 실행한다는 의미이다.
내가 동작 시간을 1분으로 해줬기 때문에 1분 동안 테스트가 진행된다. 조금 기다리다 보면 다음과 같이 테스트 결과화면이 나온다.

부하 테스트 결과 보고서 항목 설명
- Vuser (Virtual User): 99개의 가상 사용자가 동시에 시스템에 접근했다는 것을 의미한다.
- TPS (Transactions Per Second): 평균 초당 트랜잭션(요청) 수로, 834.3이라는 값은 시스템이 평균적으로 매초 834.3개의 요청을 처리할 수 있음을 나타낸다.
- 최고 TPS: 테스트 기간 동안 관찰된 최대 초당 트랜잭션 수로, 1,306.0은 테스트 중 시스템이 처리할 수 있는 최대 요청 수를 나타낸다.
- 평균 테스트시간 (Average Test Time): 요청이 처리되는 평균 시간으로, 118.02ms는 각 요청을 처리하는 데 평균적으로 118.02 밀리초가 소요되었음을 의미한다.
- 총 실행 테스트: 테스트 기간 동안 실행된 총 테스트(요청) 수로, 46,976번의 요청이 처리되었다.
- 성공한 테스트: 성공적으로 처리된 테스트 수로, 총 46,976번의 요청이 모두 성공적으로 처리되었다는 것을 의미한다.
- 에러: 테스트 중 발생한 에러의 수로, 이 경우 에러는 0으로 모든 요청이 성공적으로 처리되었다.
- 동작 시간: 부하 테스트를 실행한 총시간으로, 이 경우 1분 동안 테스트가 수행되었다.
부하 테스트에서의 TPS(Transaction Per Second), 최고 TPS, 그리고 평균 테스트 시간은 시스템의 성능을 평가하는 데 중요한 지표들이다.
- TPS는 높을수록 좋다: 이는 시스템이나 애플리케이션이 초당 처리할 수 있는 트랜잭션(요청)의 수를 의미한다. TPS가 높다는 것은 시스템이 높은 부하 하에서도 많은 요청을 효율적으로 처리할 수 있음을 나타낸다. 즉, 시스템의 처리 능력이 높고 성능이 우수함을 의미한다.
- 최고 TPS도 높을수록 좋다: 최고 TPS는 테스트 기간 중 시스템이 달성한 최대 처리 속도를 나타낸다. 이 값이 높을수록 시스템이 최적의 조건에서 더 많은 요청을 처리할 수 있는 최대 성능을 가지고 있음을 의미한다. 이는 피크 시간 동안의 시스템 성능을 이해하는 데 중요하다.
- 평균 테스트 시간은 낮을수록 좋다: 각 요청을 처리하는 데 걸리는 평균 시간이다. 이 시간이 짧을수록 사용자가 시스템이나 애플리케이션의 응답을 빠르게 받을 수 있음을 의미한다. 낮은 평균 테스트 시간은 좋은 사용자 경험과 시스템의 높은 효율성을 나타낸다.
이번 부하 테스트 결과를 보면, 모든 요청이 성공적으로 처리되었고, 에러는 발생하지 않았다. 평균 처리 시간이 118.02ms로 나타나는데, 이는 꽤 빠른 응답 시간이며, 대부분의 웹 애플리케이션에 있어 좋은 성능 지표라고 할 수 있을 것 같다. TPS 값이 평균 834.3이고 최고 1,306.0에 이르는 것을 보면, 시스템이 높은 트래픽을 효율적으로 처리할 수 있는 능력을 가지고 있음을 보여준다.
VUser와 테스트 실행 횟수의 관계
부하 테스트에서 가상 사용자(VUser) 수와 총 테스트 실행 횟수 사이의 관계는 직관적으로 이해하기 어려울 수 있다. VUser 수를 99로 설정했다고 해서 총 테스트 실행 횟수가 99번이라는 것을 의미하지는 않는다. 여기서 가상 사용자는 동시에 시스템에 요청을 보내는 사용자의 수를 나타내며, 각 가상 사용자는 테스트 기간 동안 여러 번의 요청을 보낼 수 있다.
- 가상 사용자(VUser): 동시에 시스템에 접속하거나 요청을 보내는 모의 사용자의 수를 의미한다. 이 값은 동시 사용자 수를 시뮬레이션하기 위해 설정된다.
- 총 테스트 실행 횟수: 테스트 기간 동안 모든 가상 사용자가 보낸 총요청의 수이다. 이는 가상 사용자 한 명 당 보낸 요청의 수와 테스트의 전체 기간에 따라 달라진다.
한번 가정해 보자, 99명의 가상 사용자가 각각 분당 10번의 요청을 보낸다고 할 때, 1분 동안 총 요청 수는 990번이 될 것이다. 만약 테스트가 1분 동안 진행된다면, 총 테스트 실행 횟수는 990회가 될 것이다. 이는 가상 사용자 수와 직접적으로 비례하지만, 각 사용자가 보낸 요청의 수에 따라 결정된다.
이와 같이, 총 테스트 실행 횟수는 가상 사용자(VUser)의 수, 각 사용자의 요청 빈도(스크립트에 정의된 대로), 그리고 테스트의 전체 기간에 의해 결정된다. 따라서, VUser 수가 99로 설정되었더라도, 실제 테스트 실행 횟수는 이보다 훨씬 많을 수 있으며, 이는 테스트 설정과 스크립트의 세부 사항에 따라 달라진다.
위에서 언급한 결과에서 총 실행 테스트 수가 46,976회로 나타난 것은, 99명의 가상 사용자가 테스트 기간 동안 여러 번의 요청을 보냄으로써 이루어진 결과이다. 이는 각 가상 사용자가 단순히 한 번의 요청만 보낸 것이 아니라, 여러 번의 요청을 통해 부하를 생성했음을 의미한다.
3. 시나리오 있는 테스트 스크립트 생성
이제 실제로 있을법한 시나리오 스크립트를 작성해 보자.
사용자가 로그인을 하고 마이페이지를 조회하는 프로세스를 스크립트로 작성해 보자. (로그인 및 JWT 발급, 그리고 S3에서 프로필 사진을 조회하는 로직이 포함되어 있다.)
우선 [스크립트] 메뉴로 이동한다. 그 뒤에 새로운 스크립트를 만들어준다.
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
import org.junit.Before
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import org.ngrinder.http.cookie.Cookie
import org.ngrinder.http.cookie.CookieManager
import groovy.json.JsonSlurper
/**
* 이 스크립트는 먼저 로그인을 수행하고, 로그인 성공 후 마이페이지 조회를 위한 POST 요청을 수행한다.
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
public static Map<String, String> headers = [:]
public static Map<String, Object> params = [:]
public static List<Cookie> cookies = []
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000)
test = new GTest(1, "Test1")
request = new HTTPRequest()
grinder.logger.info("before process.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("before thread.")
}
@Before
public void before() {
headers.put("Content-Type", "application/json")
// 여기서는 기본적인 헤더만 설정. 실제 토큰은 로그인 후에 설정.
grinder.logger.info("before. init headers and cookies")
}
@Test
public void test() {
def emails = ["example@email.com"]
def password = "password" // 실제 테스트 환경에 맞는 비밀번호 사용
emails.each { email ->
def loginPayload = [email: email, password: password]
// 로그인 요청
HTTPResponse loginResponse = request.POST("http://127.0.0.1:8081/auth/login", loginPayload)
if (loginResponse.statusCode == 200) {
def responseJson = new JsonSlurper().parseText(loginResponse.getBodyText())
grinder.logger.info("로그인 성공: ${responseJson}")
if (responseJson.resultCode == 'SUCCESS') {
def accessToken = responseJson.result.accessToken
def memberId = responseJson.result.memberId
def refreshToken = responseJson.result.refreshToken
grinder.logger.info("AccessToken: ${accessToken}, MemberId: ${memberId}, RefreshToken: ${refreshToken}")
// 마이페이지 조회를 위한 요청에서 사용할 헤더에 Authorization 추가
Map<String, String> authHeaders = new HashMap<>(headers)
def accessTokenString = accessToken.toString() // GString을 String으로 변환
authHeaders.put("Authorization", "Bearer " + accessTokenString)
// 마이페이지 조회 요청
request.setHeaders(authHeaders) // 요청에 헤더 설정
def myPagePayload = [targetMemberId: memberId]
HTTPResponse myPageResponse = request.POST("http://127.0.0.1:8081/member/myPage/view", myPagePayload)
if (myPageResponse.statusCode == 200) {
grinder.logger.info("마이페이지 조회 성공: 회원 ID ${memberId}")
} else {
grinder.logger.warn("마이페이지 조회 실패: HTTP 상태 코드 ${myPageResponse.statusCode}")
}
// 다음 요청을 위해 헤더 초기화
request.setHeaders(headers)
} else {
grinder.logger.warn("로그인 응답 실패: resultCode가 SUCCESS가 아님")
}
} else {
grinder.logger.warn("로그인 요청 실패: HTTP 상태 코드 ${loginResponse.statusCode}")
}
}
}
}
테스트 스크립트 로직 설명
로그인 요청
초기에 설정된 이메일과 비밀번호를 사용하여 로그인 API에 POST 요청을 보낸다. 이때, HTTPRequest 객체를 사용해 요청을 구성하고, 요청 헤더에는 "Content-Type": "application/json"을 설정하여 JSON 형식의 데이터를 전송한다.
응답 처리 및 액세스 토큰 추출
로그인 요청에 대한 응답으로 HTTP 상태 코드가 200(성공) 일 경우, 응답 본문에서 JSON 데이터를 파싱 하여 accessToken, memberId, refreshToken을 추출한다. 이 과정에서 JsonSlurper 클래스가 사용된다.
마이페이지 조회 요청
로그인 성공 후 얻은 accessToken을 사용하여 인증 헤더(Authorization)를 설정한다. 이 헤더를 포함하여 마이페이지 조회 API에 대한 POST 요청을 보낸다. 요청 파라미터로는 로그인 응답에서 얻은 memberId를 사용한다.
마이페이지 조회 응답 처리
마이페이지 조회 요청에 대한 응답을 받고, HTTP 상태 코드를 검사하여 성공 여부를 로그로 기록한다. 성공적으로 마이페이지를 조회했다면 관련 정보를 로그로 출력하고, 실패했다면 경고 메시지를 로그에 기록한다.
헤더 초기화
다음 요청을 위해 헤더 정보를 초기 상태로 복원한다. 이렇게 하여 각 테스트 사이클이 독립적으로 실행될 수 있도록 한다.
테스트 스크립트 검증 결과
이 코드를 검증해 보면 다음과 같이 잘 실행된다. (테스트 스크립트 생성 화면에서 [검증] 버튼으로 실행했다.)

4. 부하 테스트에 새로 작성한 스크립트 적용
방금 새로 작성한 '로그인-마이페이지 조회' 스크립트를 부하 테스트에 적용해 보자.
VUser는 99명으로 이전 테스트와 동일하게 해 주고 테스트 기간만 2분으로 늘려줬다.

테스트 결과는 다음과 같다.

TPS와 최고 TPS
TPS가 210이고 최고 TPS가 276으로 나타난 것은, 시스템이 초당 상당히 많은 요청을 처리할 수 있음을 보여준다. 하지만 이전 테스트 결과와 비교할 때 낮아진 TPS를 보인다면, 이번 시나리오의 처리가 더 복잡하거나 리소스를 더 많이 소모함을 의미할 수 있다.
평균 테스트 시간
467ms는 로그인, JWT 발급, 그리고 S3에서 프로필 사진을 가져오는 프로세스를 고려했을 때, 외부 시스템과의 상호작용을 포함하는 작업으로는 나쁘지 않은 응답 시간이다. 467ms는 웹 애플리케이션에 대해 일반적으로 수용 가능한 응답 시간이지만, 사용자가 느끼는 지연을 최소화하기 위해 추가적인 성능 최적화를 고려해 봐야겠다.
위 화면에서 '상세 보고서'를 클릭하면 더 자세한 항목을 볼 수 있다.

5. 테스트 스크립트 작성 방법
위에서 보시다시피 나는 테스트 스크립트를 1인 사용자(이메일 한 개)를 기준으로 작성했다. 이때 이렇게 한 명분의 내용으로 테스트 스크립트를 작성하는 게 맞는지 아니면 아예 테스트 스크립트에서 여러 명의 사용자를 기준으로 작성해야 하는지 궁금해졌다.
일단 nGrinder를 사용하여 부하 테스트를 진행할 때 테스트 스크립트를 작성하는 방법은 여러 가지가 있으며, 실제 테스트 목적과 환경에 따라 달라질 수 있다.
여기서 중요한 것은 동시에 다수의 사용자를 시뮬레이션하여 시스템이나 애플리케이션의 성능을 평가하는 것이 목표라는 점이다.
- 동일한 사용자 정보를 재사용: 현재 스크립트를 그대로 사용하여 nGrinder에서 설정한 동시 사용자 수(예: 99명)에 대해 부하 테스트를 진행하면, 모든 가상 사용자가 동일한 이메일과 비밀번호를 사용하여 로그인을 시도한다. 이 방법은 시스템이 동일한 사용자 요청을 동시에 처리할 수 있는지 테스트하는 데 유용할 수 있지만, 실제 다양한 사용자의 행동을 시뮬레이션하는 데는 한계가 있다.
- 다양한 사용자 정보 사용: 더 현실적인 시나리오를 모델링하려면 스크립트를 수정하여 다양한 사용자 정보(이메일과 비밀번호)를 사용할 수 있다. 예를 들어, 이메일 목록을 확장하고 각 가상 사용자가 목록에서 고유한 이메일을 선택하도록 할 수 있다. 이 방법은 테스트 스크립트 내에서 사용자 데이터를 동적으로 할당하는 로직을 추가해야 하므로, 스크립트가 복잡해질 수 있다. 예를 들어, CSV 파일에서 사용자 정보를 읽어오는 방식을 구현할 수 있다.
부하 테스트의 목적이 시스템의 성능을 다양한 사용자 시나리오 하에서 평가하는 것이라면, 여러 사용자 정보를 사용하는 방법이 더 적절할 수 있다. 이를 통해 로그인 시스템, 세션 관리, 데이터베이스 접근 등 다양한 컴포넌트의 성능을 보다 현실적으로 평가할 수 있다.
결론적으로, 테스트 스크립트를 그대로 두고 99명의 동시 사용자로 부하 테스트를 진행하는 경우에도 부하 테스트는 유효하게 수행된다.
하지만, 다양한 사용자 정보를 사용하여 테스트하는 것이 시스템이나 애플리케이션의 성능을 더 정확하게 평가하는 데 도움이 될 수 있다.
6. 부하 테스트 전략 소개
부하 테스트에는 다양한 전략이 있다.
베이스라인 테스트
시스템의 기본 성능 지표를 설정하는 테스트다. 일반적인 부하 조건에서의 시스템 반응을 측정한다. 시스템이 정상적인 운영 조건 하에서 안정적으로 작동하는지 확인하는 데 유용하며, 성능 기준선을 설정하는 데도 도움이 된다.
스트레스 테스트
시스템에 비정상적이거나 극단적인 부하를 적용하여 한계점을 찾는 테스트다. 이를 통해 시스템이 과부하 상태에서 어떻게 동작하는지 평가할 수 있다.
스파이크 테스트
부하의 급격한 증가나 감소를 시뮬레이션하는 테스트다. 예를 들어, 사용자 수가 짧은 시간 내에 급격히 증가하는 상황을 모방하여 시스템의 반응을 테스트한다.
내구성 테스트(Endurance Test)
장시간 동안 지속되는 부하를 시스템에 적용하는 테스트다. 이를 통해 메모리 누수나 자원 소모와 같은 장기 실행에서 발생할 수 있는 문제를 발견할 수 있다.
병목 지점 테스트
시스템 내에서 성능 병목이 발생할 수 있는 지점을 식별하는 테스트다. 이는 시스템의 성능을 개선하기 위한 중요한 단계다.
내가 지금까지 작성한 케이스는 가상 사용자를 99명으로 설정하여 실행한 '베이스라인 테스트' 전략에 속한다.
각각의 테스트 전략을 사용하는 방법도 알아보자
베이스라인 테스트
베이스라인 테스트는 애플리케이션의 기본 성능 지표를 설정하기 위해 사용된다. 이를 위해 nGrinder에서는 가상 사용자(VUser), 프로세스, 쓰레드 수를 일정 수준으로 설정하여 애플리케이션에 일정한 부하를 생성한다.
예를 들어, 각 사용자가 웹 애플리케이션의 특정 페이지를 방문하는 시나리오를 스크립트로 작성하고, 이를 50명의 가상 사용자가 동시에 실행하도록 설정할 수 있다. 이때, 테스트 기간(Test Duration)을 설정하여 테스트를 진행할 시간을 정해준다.
스트레스 테스트
스트레스 테스트는 애플리케이션의 한계점과 복구 능력을 평가하기 위해 사용된다. nGrinder에서는 가상 사용자(VUser)의 수를 점진적으로 증가시키거나, 프로세스와 쓰레드 수를 높여가며 애플리케이션에 점점 더 많은 부하를 생성한다. 이 과정에서 Ramp-up 설정을 사용하여 부하를 점진적으로 증가시키는 것이 일반적이다.
예를 들어, 1분마다 가상 사용자 수를 50명씩 증가시키며 애플리케이션이 언제 성능 저하 또는 오류를 시작하는지 관찰한다.
스파이크 테스트
스파이크 테스트는 시스템이 갑작스러운 트래픽 증가를 어떻게 처리하는지 평가하기 위해 사용된다. 이를 위해 nGrinder의 Ramp-up 설정을 사용하여 단시간 내에 가상 사용자 수를 급격히 증가시키고 감소시키는 패턴을 생성해 준다.
예를 들어, 5분 동안 가상 사용자 수를 100명에서 1000명으로 증가시켰다가 다시 감소시키는 시나리오를 설정할 수 있다.
내구성 테스트(Endurance Test)
내구성 테스트는 애플리케이션의 장기간 실행에서 발생할 수 있는 문제를 발견하기 위해 사용된다. nGrinder에서는 테스트 기간(Test Duration)을 길게 설정하여, 예를 들어 몇 시간 또는 하루 이상 동안 부하 테스트를 지속한다. 이 과정에서 메모리 누수, CPU 사용률, 디스크 I/O와 같은 시스템 자원의 사용량을 모니터링한다.
병목 지점 테스트
병목 지점을 테스트하기 위해서는 애플리케이션의 다양한 부분에 대해 세분화된 테스트를 실행해야 한다. nGrinder에서는 스크립트(Script)를 다르게 작성하여 애플리케이션의 특정 기능이나 API를 대상으로 부하 테스트를 진행한다. 성능 저하가 관찰되는 영역을 찾기 위해 다양한 설정을 실험하며, 이를 통해 애플리케이션 내 성능 병목 지점을 식별할 수 있다.
각 전략을 적용할 때는 nGrinder의 에이전트(Agent), 가상 사용자(VUser), 프로세스(Process), 쓰레드(Thread), 테스트 기간(Test Duration) 설정을 조절하며, 시스템의 성능을 다양한 측면에서 평가한다. 설정을 조정하는 방법은 nGrinder 사용자 인터페이스를 통해 직관적으로 이루어지며, 테스트 결과는 nGrinder의 대시보드에서 확인할 수 있다.
🔥 결론
이렇게 nGrinder에서 부하 테스트까지 실행해 봤다. 더 다양한 방법이 있지만 이번 글에서는 간단한 베이스라인 테스트로만 진행해 봤는데 나중에 시간이 된다면 더 다양한 방법으로 부하 테스트를 진행해 봐야겠다.
같은 팀원인 "개발자의 서랍"님의 블로그도 한번 방문해 보세요! 좋은 글이 많이 있습니다 :)
개발자의 서랍
[기록 implements 기억] 모든것을 기록하며 공유하는 주니어 백엔드 개발자
curiousjinan.tistory.com
'Tools > nGrinder' 카테고리의 다른 글
| nGrinder 스크립트 메뉴 접속 시 SqlJetException: CANTOPEN 에러 해결 (4) | 2024.02.15 |
|---|---|
| nGrinder를 사용하여 시스템 성능 한계와 최적 부하 지점 분석 (5) | 2024.02.14 |
| macOS에서 nGrinder 설치 - 엔그라인더 환경 설정 (4) | 2024.02.14 |