
지난 글에서 데이터 쪽에 학습을 여러 번 시키는 StratifiedKFold로 성능을 높였다.
이제 모델을 추론하는 쪽에서 더 강화해보겠다.
TTA
TTA로 모델 성능 개선을 해보려고 한다.
TTA는 Test Time Augmentation로 테스트 이미지에 여러 가지 변환을 적용하여 모델 예측을 강화하는 방법이다. TTA는 주로 추론 과정에서 사용되어 모델의 예측 안정성과 성능을 향상하는 데 도움을 준다.
TTA에서는 테스트 이미지에 여러 형태의 augmentations을 적용한 후 각각의 변환 이미지에 대해 예측을 수행한다. 그런 다음 모든 변환된 이미지의 예측 결과를 모아 평균 또는 최빈값을 구해 최종 예측값으로 사용한다. 이를 통해 모델이 단일 이미지에 대해 가지는 불확실성을 줄이고 예측 성능을 높일 수 있다.
예를 들어, 단일 이미지에 대해 다음과 같은 변환을 TTA로 적용할 수 있다.
- 좌우 반전
- 상하 반전
- 작은 각도로 회전
- 약간의 확대/축소
- 밝기나 대조 조정
이렇게 생성된 여러 이미지에 대해 각각 예측을 수행하고 모든 예측 결과를 평균하거나 최빈값을 선택하여 최종 클래스를 결정한다.
이미지 분류 모델에서 TTA의 장점
- 불확실성 감소: TTA를 사용하면 모델이 예측하는 다양한 변환된 이미지를 통해 보다 강건한 예측을 얻을 수 있다.
- 성능 향상: 원본 이미지의 단일 예측보다 여러 번 예측을 종합해 결과를 도출하므로, 정확도가 향상될 가능성이 높다.
학습 데이터셋에 augmentation 주는 거랑 뭐가 다를까?
현재 데이터 분포는 학습 데이터는 정상 이미지이고 테스트 데이터에는 심한 노이즈가 껴있는 이미지 데이터다. 그래서 노이즈가 심한 이미지를 제대로 추론하기 위해 학습데이터셋에 노이즈를 추가해서 학습하고 있었다.
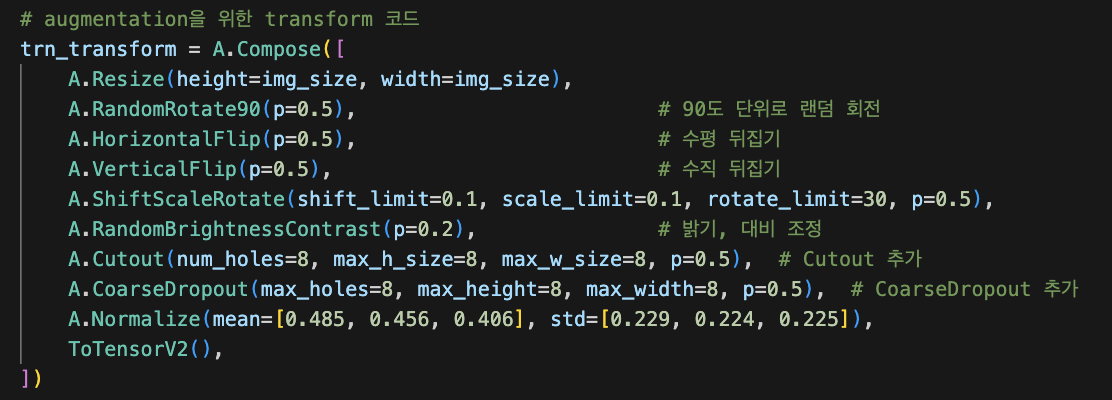
trn_transform은 학습 데이터에 대해 데이터 증강을 수행 해 모델이 다양한 변형에 대해 학습하도록 돕는 것이 목적이다. 이와 달리 TTA는 학습 과정이 아니라 테스트 과정에서 여러 변환된 이미지를 사용해 예측을 강화하는 방법이다.
현재 설정만으로는 TTA가 적용되지 않은 상태다. 테스트 데이터에 대해서도 학습과 비슷한 여러 변형을 적용하고 각 변형에 대한 예측을 통해 최종 예측값을 평균 또는 최빈값으로 결합해야 TTA 효과를 낼 수 있다.
TTA 적용
이제 TTA를 적용해보자.
tst_transform에 여러 가지 변형을 추가한 후 각 변형된 이미지에 대해 예측을 수행하고 최빈값을 도출해 예측을 결정한다.
# TTA용 변환 정의
tta_transforms = [
A.Compose([
A.Resize(height=img_size, width=img_size),
A.HorizontalFlip(p=1.0),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]),
A.Compose([
A.Resize(height=img_size, width=img_size),
A.VerticalFlip(p=1.0),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]),
A.Compose([
A.Resize(height=img_size, width=img_size),
A.RandomBrightnessContrast(p=1.0, brightness_limit=0.2, contrast_limit=0.2),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]),
# 원본 이미지 (변형 없음)
tst_transform
]def tta_predict(model, image, device, tta_transforms):
model.eval() # 평가 모드로 설정
predictions = []
# TTA 적용된 이미지들에 대한 예측 수행
for transform in tta_transforms:
augmented_image = transform(image=image)['image']
augmented_image = augmented_image.to(device).unsqueeze(0) # 배치 차원 추가
with torch.no_grad():
preds = model(augmented_image)
logits = preds.logits if hasattr(preds, 'logits') else preds
predicted_class = logits.argmax(dim=1).cpu().numpy() # 클래스 예측
predictions.append(predicted_class)
# 최빈값 계산
final_prediction = mode(predictions, axis=0)[0][0]
return final_prediction# 각 폴드의 학습 완료 후 전체 테스트 데이터셋(tst_loader)에서 예측 수행
fold_predictions = []
model.eval()
with torch.no_grad():
for images, _ in tst_loader:
batch_predictions = []
for image in images: # 배치 내 각 이미지를 개별적으로 처리
image_np = image.permute(1, 2, 0).cpu().numpy()
pred = tta_predict(model, image_np, device, tta_transforms)
batch_predictions.append(pred)
fold_predictions.extend(batch_predictions)이렇게 해보니까 각 fold별로 전부 동일한 클래스로 예측하는 에러가 발생했다.
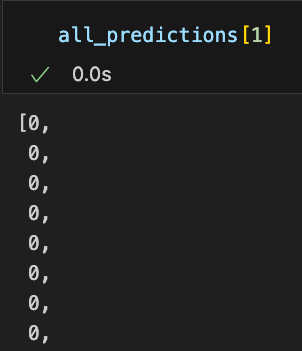
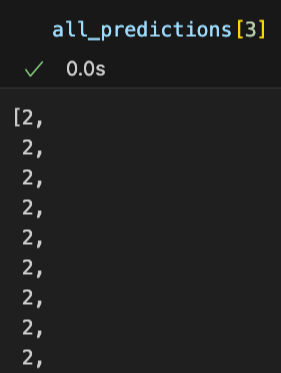
일단 지금 tta를 적용하고 각 이미지에 대해서 어떤 예측값을 하는지 프린트해봤는데 같은 fold안에서는 다른 이미지여도 하나의 클래스로 예측하는게 발견됐다....
TTA 코드의 문제라기 보다는 지금 다른 문제가 있는거같다....
일단 이 문제는 왜그런지 해결을 못했다...ㅜㅠㅜㅠ
다시 새롭게 데이터 증강뿐만 아니라 하이퍼 파라미터를 수정해보자! 해서 fold와 epoch 수를 조정해봤다.
fold 수 늘리기
학습 데이터셋이 부족한 상황에서는 epoch 수를 늘리는것보다 fold 수를 늘리는 것이 일반적으로 더 낫다고 한다.왜냐하면 더 많은 데이터로 학습할 수 있는 기회를 제공하기 때문이다.
1. epoch을 늘리는 방법 (10 → 15)
- 장점: 모델이 같은 데이터를 반복 학습하면서, 학습이 충분히 이루어질 가능성이 커진다.
- 단점: 데이터가 부족한 경우, epoch을 많이 늘리면 과적합이 발생할 위험이 크다. 특히 작은 데이터셋에서 성능 향상을 위해 epoch을 늘리면 훈련 데이터에 특화된 패턴만 학습하게 되는 경향이 있다.
2. fold 수를 늘리는 방법 (5 → 10)
- 장점: k-fold 수를 늘리면 모델이 학습에 사용하는 데이터 비율이 증가하므로 더 많은 데이터로 학습하는 효과가 있다. 예를 들어 5-fold에서는 약 80%의 데이터를 학습에 사용하고 10-fold에서는 90%의 데이터를 학습에 사용한다. 데이터가 부족할 때 중요한 장점이다.
- 단점: fold 수를 늘리면 모델을 학습하는 데 걸리는 시간이 증가한다. 하지만 데이터가 적은 상황에서는 모델의 일반화 성능을 높일 수 있으므로 epoch을 늘리는 것보다 유리할 가능성이 높다.
결론
데이터가 부족한 상황에서는 fold 수를 늘려 다양한 데이터로 학습하는 것이 과적합 위험을 줄이고 일반화 성능을 높이는 데 유리할 수 있다.
그래서 fold를 10으로 늘려서 돌려보니 0.8243이 되었다. (현재 최고성능 0.8460)
현재는 지금 데이터셋 문제가 가장 큰것같기 때문에 데이터쪽을 더 찾아봐야겠다...
일단은 오늘은 여기서 마무리,,,
'Upstage AI Lab 4기' 카테고리의 다른 글
| [CV 경진대회] 최종 제출, 자체 평가 및 회고 (1) | 2024.11.08 |
|---|---|
| [CV 경진대회] offline 데이터 증강 그리고 하이퍼파라미터 수정 (7) | 2024.11.07 |
| [CV 경진대회] K-fold 적용 (1) | 2024.11.04 |
| [CV 경진대회] 데이터 증강 기법, ViT 모델 사용 (0) | 2024.11.04 |
| [Upstage AI Lab 4기] '아파트 실거래가 예측' 경진대회 Private Rank 3등 후기 (1) | 2024.09.17 |
지난 글에서 데이터 쪽에 학습을 여러 번 시키는 StratifiedKFold로 성능을 높였다.
이제 모델을 추론하는 쪽에서 더 강화해보겠다.
TTA
TTA로 모델 성능 개선을 해보려고 한다.
TTA는 Test Time Augmentation로 테스트 이미지에 여러 가지 변환을 적용하여 모델 예측을 강화하는 방법이다. TTA는 주로 추론 과정에서 사용되어 모델의 예측 안정성과 성능을 향상하는 데 도움을 준다.
TTA에서는 테스트 이미지에 여러 형태의 augmentations을 적용한 후 각각의 변환 이미지에 대해 예측을 수행한다. 그런 다음 모든 변환된 이미지의 예측 결과를 모아 평균 또는 최빈값을 구해 최종 예측값으로 사용한다. 이를 통해 모델이 단일 이미지에 대해 가지는 불확실성을 줄이고 예측 성능을 높일 수 있다.
예를 들어, 단일 이미지에 대해 다음과 같은 변환을 TTA로 적용할 수 있다.
- 좌우 반전
- 상하 반전
- 작은 각도로 회전
- 약간의 확대/축소
- 밝기나 대조 조정
이렇게 생성된 여러 이미지에 대해 각각 예측을 수행하고 모든 예측 결과를 평균하거나 최빈값을 선택하여 최종 클래스를 결정한다.
이미지 분류 모델에서 TTA의 장점
- 불확실성 감소: TTA를 사용하면 모델이 예측하는 다양한 변환된 이미지를 통해 보다 강건한 예측을 얻을 수 있다.
- 성능 향상: 원본 이미지의 단일 예측보다 여러 번 예측을 종합해 결과를 도출하므로, 정확도가 향상될 가능성이 높다.
학습 데이터셋에 augmentation 주는 거랑 뭐가 다를까?
현재 데이터 분포는 학습 데이터는 정상 이미지이고 테스트 데이터에는 심한 노이즈가 껴있는 이미지 데이터다. 그래서 노이즈가 심한 이미지를 제대로 추론하기 위해 학습데이터셋에 노이즈를 추가해서 학습하고 있었다.
trn_transform은 학습 데이터에 대해 데이터 증강을 수행 해 모델이 다양한 변형에 대해 학습하도록 돕는 것이 목적이다. 이와 달리 TTA는 학습 과정이 아니라 테스트 과정에서 여러 변환된 이미지를 사용해 예측을 강화하는 방법이다.
현재 설정만으로는 TTA가 적용되지 않은 상태다. 테스트 데이터에 대해서도 학습과 비슷한 여러 변형을 적용하고 각 변형에 대한 예측을 통해 최종 예측값을 평균 또는 최빈값으로 결합해야 TTA 효과를 낼 수 있다.
TTA 적용
이제 TTA를 적용해보자.
tst_transform에 여러 가지 변형을 추가한 후 각 변형된 이미지에 대해 예측을 수행하고 최빈값을 도출해 예측을 결정한다.
# TTA용 변환 정의
tta_transforms = [
A.Compose([
A.Resize(height=img_size, width=img_size),
A.HorizontalFlip(p=1.0),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]),
A.Compose([
A.Resize(height=img_size, width=img_size),
A.VerticalFlip(p=1.0),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]),
A.Compose([
A.Resize(height=img_size, width=img_size),
A.RandomBrightnessContrast(p=1.0, brightness_limit=0.2, contrast_limit=0.2),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]),
# 원본 이미지 (변형 없음)
tst_transform
]
def tta_predict(model, image, device, tta_transforms):
model.eval() # 평가 모드로 설정
predictions = []
# TTA 적용된 이미지들에 대한 예측 수행
for transform in tta_transforms:
augmented_image = transform(image=image)['image']
augmented_image = augmented_image.to(device).unsqueeze(0) # 배치 차원 추가
with torch.no_grad():
preds = model(augmented_image)
logits = preds.logits if hasattr(preds, 'logits') else preds
predicted_class = logits.argmax(dim=1).cpu().numpy() # 클래스 예측
predictions.append(predicted_class)
# 최빈값 계산
final_prediction = mode(predictions, axis=0)[0][0]
return final_prediction
# 각 폴드의 학습 완료 후 전체 테스트 데이터셋(tst_loader)에서 예측 수행
fold_predictions = []
model.eval()
with torch.no_grad():
for images, _ in tst_loader:
batch_predictions = []
for image in images: # 배치 내 각 이미지를 개별적으로 처리
image_np = image.permute(1, 2, 0).cpu().numpy()
pred = tta_predict(model, image_np, device, tta_transforms)
batch_predictions.append(pred)
fold_predictions.extend(batch_predictions)이렇게 해보니까 각 fold별로 전부 동일한 클래스로 예측하는 에러가 발생했다.
일단 지금 tta를 적용하고 각 이미지에 대해서 어떤 예측값을 하는지 프린트해봤는데 같은 fold안에서는 다른 이미지여도 하나의 클래스로 예측하는게 발견됐다....
TTA 코드의 문제라기 보다는 지금 다른 문제가 있는거같다....
일단 이 문제는 왜그런지 해결을 못했다...ㅜㅠㅜㅠ
다시 새롭게 데이터 증강뿐만 아니라 하이퍼 파라미터를 수정해보자! 해서 fold와 epoch 수를 조정해봤다.
fold 수 늘리기
학습 데이터셋이 부족한 상황에서는 epoch 수를 늘리는것보다 fold 수를 늘리는 것이 일반적으로 더 낫다고 한다.왜냐하면 더 많은 데이터로 학습할 수 있는 기회를 제공하기 때문이다.
1. epoch을 늘리는 방법 (10 → 15)
- 장점: 모델이 같은 데이터를 반복 학습하면서, 학습이 충분히 이루어질 가능성이 커진다.
- 단점: 데이터가 부족한 경우, epoch을 많이 늘리면 과적합이 발생할 위험이 크다. 특히 작은 데이터셋에서 성능 향상을 위해 epoch을 늘리면 훈련 데이터에 특화된 패턴만 학습하게 되는 경향이 있다.
2. fold 수를 늘리는 방법 (5 → 10)
- 장점: k-fold 수를 늘리면 모델이 학습에 사용하는 데이터 비율이 증가하므로 더 많은 데이터로 학습하는 효과가 있다. 예를 들어 5-fold에서는 약 80%의 데이터를 학습에 사용하고 10-fold에서는 90%의 데이터를 학습에 사용한다. 데이터가 부족할 때 중요한 장점이다.
- 단점: fold 수를 늘리면 모델을 학습하는 데 걸리는 시간이 증가한다. 하지만 데이터가 적은 상황에서는 모델의 일반화 성능을 높일 수 있으므로 epoch을 늘리는 것보다 유리할 가능성이 높다.
결론
데이터가 부족한 상황에서는 fold 수를 늘려 다양한 데이터로 학습하는 것이 과적합 위험을 줄이고 일반화 성능을 높이는 데 유리할 수 있다.
그래서 fold를 10으로 늘려서 돌려보니 0.8243이 되었다. (현재 최고성능 0.8460)
현재는 지금 데이터셋 문제가 가장 큰것같기 때문에 데이터쪽을 더 찾아봐야겠다...
일단은 오늘은 여기서 마무리,,,
'Upstage AI Lab 4기' 카테고리의 다른 글
| [CV 경진대회] 최종 제출, 자체 평가 및 회고 (1) | 2024.11.08 |
|---|---|
| [CV 경진대회] offline 데이터 증강 그리고 하이퍼파라미터 수정 (7) | 2024.11.07 |
| [CV 경진대회] K-fold 적용 (1) | 2024.11.04 |
| [CV 경진대회] 데이터 증강 기법, ViT 모델 사용 (0) | 2024.11.04 |
| [Upstage AI Lab 4기] '아파트 실거래가 예측' 경진대회 Private Rank 3등 후기 (1) | 2024.09.17 |