
프롬프트 전략
프롬프트 전략은 LLM에게 보다 정확하고 효과적인 답변을 유도하기 위한 입력 방식이다. 다양한 전략을 활용해 모델이 단계적 사고 과정을 따르거나, 감정에 반응하는 방식으로 개선된 성능을 유도할 수 있다.
Chain-of-Thought (CoT)
Chain-of-Thought는 모델이 문제 해결을 위해 단계별로 논리적인 사고 과정을 따르도록 유도하는 프롬프트 방식이다. 이 방식은 주로 복잡한 문제를 해결할 때 유용하고 각 단계를 명시적으로 제시해 모델이 점진적으로 답을 구성하도록 한다.
Chain-of-Thought (CoT) 프롬프트 전략을 사용할 때 모델의 응답 성능이 향상되는 이유는 바로 문제 해결 과정을 단계별로 설명하도록 유도하기 때문이다.
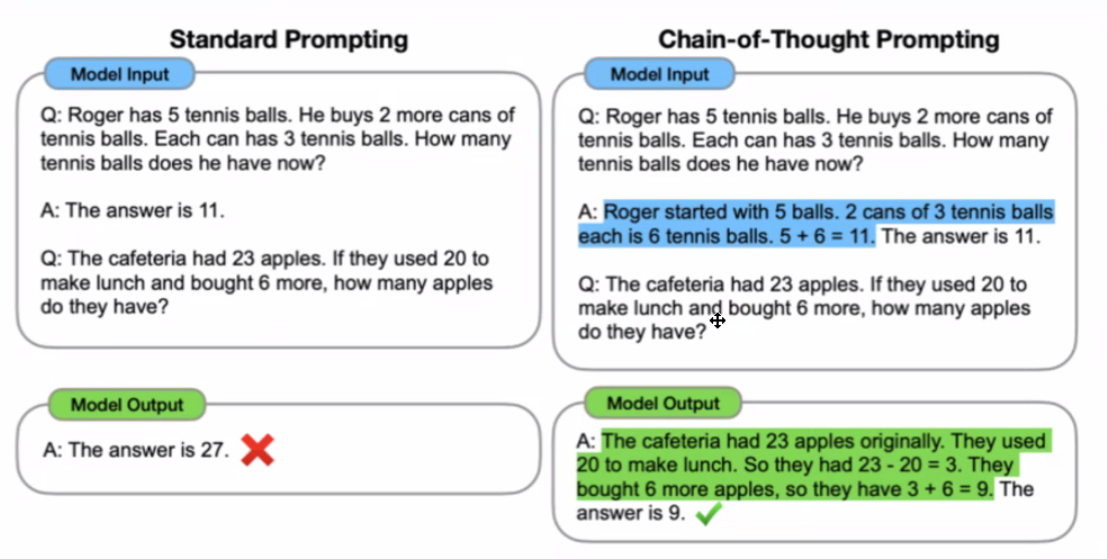
왼쪽 표의 일반 프롬프트에서는 모델이 단순히 답을 “The answer is 11”이라고 제시하지만 구체적인 과정 없이 결과만 제공하다 보니 복잡한 문제를 풀 때 오답이 나오는 경우가 생긴다.
오른쪽의 CoT 프롬프트 방식에서는 모델이 단계적으로 사고 과정을 설명하면서 답변을 생성하도록 유도된다. 예를 들어, 문제를 단계별로 나누어 “처음에 테니스 공 5개가 있었고, 추가로 2개의 캔을 샀으며, 각 캔에 3개의 테니스 공이 있으므로 총 6개의 공을 더했다”는 식으로 하나씩 설명하는 과정을 통해 모델이 논리적 흐름을 따라 답을 도출하게 된다. 이러한 사고 과정이 포함되면, 모델은 각 단계에서 중간 계산을 확인하면서 답을 확인하기 때문에 최종 답변의 정확성이 높아진다.
Program-of-Thought (PoT)
Program-of-Thought (PoT) 프롬프트 전략은 모델이 복잡한 문제를 해결할 때 사고 과정을 코드 작성 방식으로 표현하도록 유도하는 방식이다. 이 전략은 수학 문제나 논리적인 계산을 요구하는 문제에서 특히 유용하다.
PoT는 모델이 문제를 단계적으로 이해하고 이를 코드로 구현하면서 정확한 답을 도출할 수 있도록 돕는다.

이미지에서 PoT 프롬프트는 이진수 덧셈과 뺄셈을 수행하는 문제를 다루고 있다. 문제는 이진수로 주어진 여러 수를 계산한 뒤 그 결과를 이진수로 표현하라는 요구사항이 포함되어 있다. 이 문제를 단순히 하나의 답변으로 응답하려고 하면 실수가 발생할 가능성이 높지만 PoT 전략을 사용하면 모델이 계산의 각 단계를 코드로 작성하면서 보다 정확하게 풀 수 있다.
예를 들어, PoT 프롬프트 방식에서는 아래와 같은 과정을 따른다:
- 문제 분석 및 변수 정의: 모델은 먼저 이진수를 10진수로 변환하여 각 값을 변수로 정의한다. 이미지 속 예시에서는 각각의 이진수를 10진수로 변환해 변수 num1, num2, num3, num4로 저장한다.
- 연산 수행: 변환된 10진수 값들을 덧셈과 뺄셈 연산을 통해 계산한다. 예제에서는 num1 + num2 - num3 + num4와 같은 식을 통해 계산이 이루어진다. 이 과정에서 각 중간 단계는 명확하게 정의되어 있어서 계산의 흐름을 따르기 쉽다.
- 결과 변환 및 출력: 최종적으로 연산 결과를 이진수로 변환하여 답변으로 반환한다. 이처럼 PoT 전략은 문제 해결 과정을 코드 블록으로 표현하여 모델이 단계적으로 논리적 사고를 진행하도록 돕는다.
PoT 전략을 사용하면 모델이 문제를 단순히 텍스트로 표현하는 것보다 계산과정을 코드로 구현해 오류를 줄일 수 있다. 중간 계산 단계와 변수 정의, 결과 변환을 포함한 각 단계가 명확하게 제시되기 때문에 복잡한 문제에서도 높은 정확도를 유지할 수 있다.
즉, PoT는 모델이 논리적이고 정밀한 계산 과정을 따르도록 하여 복잡한 수학적 문제나 논리적 문제에서도 효과적인 답변을 생성하도록 돕는 전략이다.
Others
기타 전략에는 모델의 성능을 높이기 위해 감정적인 요소를 추가하거나 독려하는 방법이 있다. 예를 들어, 모델에게 “take a deep breath”와 같은 프롬프트를 추가하면 성능이 향상되는 경우가 있다. 이는 모델이 답변을 생성할 때 보다 차분하고 신중한 접근을 하도록 유도할 수 있기 때문이다.

혹은 프롬프트에 '나 이 문제 못 풀면 진짜 죽어.. 교수님한테 혼나,, 나 졸업 못해,,' 라거나 아니면 존댓말로 질문하면 더 성능이 좋아진 걸 볼 수 있다.
프롬프트 전략을 통해 모델이 문제 해결 과정을 구조화하고 논리적으로 접근하도록 유도하는 다양한 기법을 살펴보았다. 이제, 이러한 프롬프트 전략을 RAG 모델에 적용하여 어떻게 성능을 향상시킬 수 있는지 알아보자.
특히, RAG에서 중요한 것은 모델이 외부 정보를 효과적으로 Retrieval하여 필요한 답변을 Generation하는 방식이다. 이를 위해 다양한 검색 전략을 사용할 수 있으며, 여기에는 Hybrid Search, Query Expansion, 그리고 여러 파이프라인의 조합이 포함된다. 각 전략은 RAG 모델이 더 정확하고 풍부한 정보를 찾고 활용할 수 있도록 돕는다.
Retrieval Strategy
Hybrid Search
Hybrid Search는 키워드 검색과 벡터 검색을 결합하여 각각의 장점을 모두 활용하는 검색 방식이다.

- 키워드 검색: 사용자가 입력한 쿼리와 문서 내 키워드를 직접 매칭하여 가장 빈도수가 높은 문서를 반환한다. 이 방식은 정확한 단어나 구문이 중요한 경우에 유용하다.
- 벡터 검색: 쿼리를 벡터화하여 각 문서와의 유사도를 계산한다. 이를 통해 단순히 동일한 단어를 찾는 것을 넘어서 의미적으로 유사한 문서까지 포함하여 검색할 수 있다.
두 방식의 결과를 종합하여 관련성 높은 순서로 reranking함으로써 RAG가 더 풍부하고 유의미한 정보를 검색할 수 있도록 돕는다. 이렇게 Hybrid Search를 사용하면, 키워드와 의미적 유사성 모두를 고려하여 검색 품질이 개선된다.
Query Expansion
Query Expansion은 사용자의 쿼리를 확장하여 더 많은 정보를 검색할 수 있게 하는 전략이다. LLM을 통해 사용자가 의도한 쿼리를 보다 풍부하게 해석하고 관련된 키워드를 추가하여 검색을 확장한다. 예를 들어, 사용자가 단어 하나만 입력하더라도 그와 의미적으로 관련된 용어나 주제를 추가해 더 다양한 문서를 검색할 수 있도록 한다.
초기 쿼리가 단순하거나 모호할 경우에도 쿼리 확장을 통해 모델이 더 유의미한 검색 결과를 얻을 수 있으며, 검색된 문서에서 더 많은 정보를 바탕으로 응답을 생성할 수 있다.

사용자가 하나의 간단한 쿼리를 입력하면, 이 쿼리는 그 자체로 충분히 구체적이지 않을 수 있다. 예를 들어, “스페이스 셔틀”이라는 단어만 입력했을 때 사용자가 관심을 가지는 내용이 단순히 셔틀에 관한 일반 정보인지, 특정 시스템에 대한 세부적인 내용인지 모호할 수 있다.
Query Expansion에서는 원래 쿼리를 기반으로 여러 가지 하위 쿼리를 생성한다. 이때 각 하위 쿼리는 원래 쿼리의 의도를 다른 방향으로 해석한 것이다. 예를 들어, “스페이스 셔틀”이라는 쿼리에서 다음과 같은 다양한 하위 쿼리가 생성될 수 있다:
- “스페이스 셔틀의 추진 시스템”
- “스페이스 셔틀의 구조적 안전성”
- “스페이스 셔틀의 발사 성공률”
이러한 하위 쿼리들은 원래 쿼리의 주제를 확장하여 세부적인 방향으로 파고드는 역할을 한다.
생성된 하위 쿼리들은 각각 독립적으로 검색을 수행한다. 각 하위 쿼리로 검색된 결과들이 모이면, 이를 다시 한번 종합하여 관련성이 높은 순서로 reranking 과정을 거치게 된다. 이 과정을 통해 가장 관련성이 높은 정보를 상단에 배치하여 최종적으로 사용자에게 제시할 정보를 선정한다.
최종적으로 가장 관련성이 높은 정보가 포함된 문서들이 사용자에게 제공된다. Query Expansion을 통해 검색 범위가 넓어지고, 결과적으로 사용자 쿼리에 대한 더 풍부한 정보를 담은 응답이 생성된다.
실제 현업에서 RAG
현실적인 RAG 응용에서는 사용자의 의도와 질문 유형에 따라 서로 다른 데이터베이스에서 정보를 검색하거나 답변을 생성할 필요가 있다. 이를 위해 다중 파이프라인을 설정할 수 있다.

예를 들어, 사용자가 특정 분야의 정보를 요청하면 그에 맞는 데이터베이스에서 정보를 검색하고 특정 질문에는 답변을 회피해야 하는 경우 규칙 기반 시스템(rule-based system)으로 응답을 제한할 수 있다. 이런 방식으로 다양한 검색 파이프라인을 조합해 RAG가 상황에 맞는 정확한 답변을 생성할 수 있게 된다.
다중 파이프라인 설정을 통해 RAG는 단일 파이프라인보다 더 유연하게 다양한 정보 소스에 접근할 수 있고 사용자에게 더 신뢰성 높은 답변을 제공할 수 있다.
Instruction Tuning
Instruction Tuning은 모델이 사용자의 질문에 대해 보다 정확하고 일관된 응답을 생성하도록 학습시키는 새로운 접근 방식이다. 기존의 Pre-training이나 Fine-tuning과는 다르게 사용자의 질문을 학습의 주요 요소로 삼는 것이 아니라 질문을 지시 조건(instruction)으로 설정하고, 모델이 응답 자체를 학습하도록 한다.
기존 Fine-tuning 방식에서는 모델이 질문과 응답의 단어 매칭이나 구조에 따라 학습해 입력된 질문에 대응하는 답변을 생성하는 데 집중했다. 반면 Instruction Tuning은 질문을 일종의 조건으로만 사용하고 실제 학습의 대상은 어시스턴트의 “응답”이다. 이를 통해 모델은 질문의 세부 단어보다는 질문에 적절한 “응답 방식과 구조”를 학습하여, 새로운 질문에도 일관된 응답을 생성할 수 있는 능력을 기르게 된다.
결국 Instruction Tuning의 핵심은 모델이 User의 질문 자체를 학습하는 것이 아니라, Assistant의 “응답”을 학습하도록 하는 것이다. 즉, 모델의 학습 목표는 사용자 질문에 대한 응답이 얼마나 정확하고 일관된 지를 평가하는 응답 손실(response loss)에만 집중하는 것이다.

기존 Fine-tuning에서는 모델이 질문의 세부 구조나 단어까지 학습하여 질문에 맞는 답변을 생성하려고 했다. 그러나 Instruction Tuning은 질문을 조건으로 보고, 어시스턴트의 답변에만 집중해서 모델이 얼마나 정확하게 응답하는지 평가한다. 이를 통해 모델은 개별적인 질문에 집착하지 않고, 응답 자체의 품질을 최대화하는 방향으로 학습된다.
모델은 질문의 단어 하나하나에 맞추기보다, 질문에 대한 적절한 응답을 생성하는 방법에 집중하게 된다. “Response Loss” 기반의 학습을 통해 모델은 새로운 질문에 대해 답변할 때도 일관된 형식과 논리를 유지할 수 있다. Response Loss에만 초점을 맞추면, 모델이 더 다양한 질문 유형에 유연하게 대응할 수 있는 장점이 있다.
즉, 동일한 주제의 다양한 질문에 대해 모델이 유사한 수준의 응답 품질을 유지할 수 있다.
Instruction Tuning은 모델이 다양한 질문 유형에 대해 일관된 답변을 생성하기 위해 대량의 학습 데이터를 필요로 한다. 그 이유는 다음과 같다:
- 다양한 질문과 상황에 적응: 모델이 수많은 질문 상황에서 유사한 응답 구조와 논리를 통해 일관된 답변을 생성하려면, 다양한 질문과 응답을 충분히 학습해야 한다. 이렇게 해야만 모델이 새로운 상황에도 적절히 대응할 수 있는 능력을 갖출 수 있다.
- 다양한 응답 방식의 학습: Instruction Tuning은 모델이 특정 질문에 대한 정답을 학습하는 것이 아니라, 여러 상황에서 응답을 구성하는 방식을 학습하게 한다. 다양한 질문 유형과 응답 예시가 포함된 데이터가 많아질수록, 모델은 더 넓은 범위의 질문에 대해 적절하게 반응할 수 있게 된다.
- 질문에 대한 유연한 대응 능력 강화: Instruction Tuning은 모델이 단순히 질문에 대응하는 것이 아니라, 응답의 일관성과 품질을 높이는 데 초점을 맞춘다. 이를 위해서는 다양한 질문 상황에 대한 학습 데이터가 필요하며, 이를 통해 모델은 질문의 세부적인 차이를 넘어 일관성 있는 답변을 생성하는 능력을 갖출 수 있다.\
합성 데이터의 필요성과 역할
Instruction Tuning에서는 방대한 양의 데이터가 필요하지만 실제 데이터 수집이 어려운 경우가 많다. 이를 해결하기 위해 합성 데이터가 사용된다.
합성 데이터는 LLM 자체가 학습에 사용할 데이터를 생성하는 방식으로 실제 데이터가 부족한 상황을 보완한다. 예를 들어, 모델에게 특정 주제에 대한 다양한 질문을 스스로 만들어내도록 하여 학습 데이터로 활용할 수 있다. 합성 데이터를 활용하면 실제 사용자 질문 데이터가 충분하지 않을 때에도 모델이 다양한 질문과 응답 유형에 대해 훈련될 수 있다. 합성 데이터는 실제 데이터와 유사한 형식을 갖고 있기 때문에 모델이 실제 질문에 대해서도 일관성 있고 적절한 응답을 생성할 수 있는 기반이 된다.
다양한 질문과 응답 사례를 학습한 모델은 새로운 질문에도 자연스럽고 일관된 답변을 제공할 수 있다. 합성 데이터는 이 과정에서 중요한 역할을 하고 Instruction Tuning의 성능을 높이는 데 기여한다.
'RAG' 카테고리의 다른 글
| ColBERT와 OpenAI로 RAG 구현하기: LLM과 검색엔진을 결합한 대화형 정보 검색(IR) 시스템 (2) | 2024.12.11 |
|---|---|
| [RAG] RAG와 Fine-Tuning 차이점과 Small Language Models (SLM) (2) | 2024.08.30 |
| [RAG] RAG 파이프라인 (1) | 2024.08.30 |
| Bert와 GPT 차이점 (1) | 2024.08.30 |
| [RAG] RAG의 기본 개념 및 트랜스포머 어텐션 설명 (1) | 2024.08.19 |