
경진대회 개요
이번 경진대회는 질문과 이전 대화 히스토리를 보고 참고할 문서를 검색 엔진에서 추출 후 이를 활용해서 질문에 적합한 대답을 생성하는 태스크다.
경진대회 기간은 12.16 - 12.19 4일간 진행되었다.
평가기준은 MAP(Mean Average Precision)을 변형해서 질문별 적합 문서 추출 정확도를 측정하며, 과학 상식 질문이 아닌 경우 검색 결과가 없을 때 1점을 부여하는 로직을 추가로 적용되었다. 제출된 결과는 eval.jsonl을 통해 자동 평가된다.
준비된 데이터셋은 다음과 같이 과학 지문이다.

최종 output jsonl 파일 형식은 다음과 같다.

구현 범위 요약

다음은 이번 경진대회 때 우리 팀에서 구현한 범위를 도식화한 거다.
파란 박스의 숫자는 큰 의미는 없고 각각 큰 섹션에 대해서 설명해보려고 한다.
1. 검색이 필요한 메시지 식별
우선 이 경진대회의 가장 중요한 건 만약 사용자 질문이 과학 관련 질문일 때만 standalone query를 생성하고 (Search API) 검색 엔진에서 문서를 추출하고 이를 topk에 넣어주고, 만약 과학 관련 질문이 아닐 때는 topk가 비워져있있을 때 가산점이 부여되는 방식이었다.
그렇기 때문에 LLM의 function calling을 이용해서 사용자 질문이 과학질문인지 아닌지 판별하는 게 굉장히 중요했다. 그러나 "과학 상식 질문"이라는 게 굉장히 모호했다. 과학 상식 여부가 애매한 질문으로 인해서 Search API 호출이 누락되는 사례가 발견된 거다. 그래서 일단 모든 질문에 대해서 topk를 '비워진 상태'로 제출해서 평가 점수를 확인해 봤다.
이렇게 했을 때 점수는 0.0909가 나왔다.

왼쪽은 MAP 점수고 우측은 MRR 점수다.
이를 기반으로 적절한 Search API 호출이 이루어져야 할 프롬프트로 수정했다.
이렇게 최종적으로 완성된 프롬프트는 다음과 같다.
검색이 필요한 경우에는 한국어 standalone query 생성 및 Search API 호출하고, 검색이 불필요한 경우에는 'NA'로 응답을 처리하게 했다.
persona_function_calling = """
## Role: 지식 전문가
## Instruction
당신의 역할은 앞의 대화 내용과 user의 질문이 추가적인 검색을 필요로 하는 경우 search API를 호출하는 것입니다.
우리는 검색서비스를 만들고 있으므로, 검색이 필요한 질문에 대해 검색이 실행되지 않는 것은 가장 큰 문제입니다.
예를 들어, 손톱의 역할에 대해 말해줘. 등과 같이 추가적인 정보를 필요로 하는 경우에 모두 search API를 호출해야 합니다.
검색을 위해 standalone_query는 반드시 한글로 작성되어야 합니다. 만약 질문이 영어로 작성되었다면, standalone_query를 한국어로 번역하여 반환하세요.
예를 들어 'John Smith'와 같이 영문으로 된 이름의 경우 '존 스미스'처럼 한글로 생성하세요.
단, 대화 내용이 일상적인 대화에 해당되는 경우에는 절대로 search API를 호출하지 말고, 텍스트 'NA'로 답변하세요. (예: 너는 누구니)
그 밖에 검색에 필요한 대화에 대해서는 모두 search API를 호출하세요.
"""
2. 메타데이터 추가 생성
검색엔진에서 문서 추출을 더 잘하기 위해서 메타데이터도 추가로 생성해 줬다. ES에서 형태소 분석기 kiwi, nori를 바꿔가면서 진행해 줬는데 멘토분이 사실 ES 성능이 많이 올라와서 형태소 분석기의 차이가 미비할 거라는 말을 해주셨다. 그래서 일단 nori로 고정을 하고 어떻게 하면 질문에 더 적절한 문서를 찾아올까 고민하다가 메타데이터를 생각해 냈다.
메타데이터 생성
메타데이터를 생성할 때 다음과 같이 만들었다.
- title 제목
- 문서의 핵심 내용을 간결하게 요약한 대표 문구
- 문서를 빠르게 이해할 수 있도록 함
- keywords (키워드)
- 문서의 주요 주제를 나타내는 핵심 단어 목록.
- 검색 및 분류에 용이하도록 함.
- summary (요약)
- 문서의 내용을 2~3 문장으로 요약한 간략한 설명.
- 문서의 주요 내용을 빠르게 파악 가능.
- categories (카테고리)
- 문서와 관련된 분야 또는 과학적 주제 목록.
- 문서의 주제를 분류하여 탐색성과 조직화를 높임.
메타데이터 포함해서 검색
그리고 문서를 검색할 때 Boolean Query를 이용해서 메타 데이터별 가중치를 설정해 줬다.
- title → 가중치 1.5
- keywords → 가중치 1.3
- summary → 가중치 1.2
- content → 가중치 1.0
이렇게 문서의 제목과 키워드를 우선적으로 반영하여 검색 품질을 개선했다.
최종적으로 완성된 메타데이터는 다음과 같다.

3. 임베딩 모델 선정
Vector search에 사용할 임베딩 모델에 대해서도 알아봤다. 사실 이렇게 임베딩 모델을 변경하면 성능이 좋아진다는 걸 경진대회 마지막날에 알게 되어서 여러 실험을 진행해보진 못했다..
크기가 크고, 성능이 좋은 모델
dragonkue/bge-m3-ko
- 장점 : 비교적 최신 모델이며 한국어에 특화된 모델로, 한국어 텍스트의 의미를 더 정확하게 포착할 수 있다. (BGE-M3를 한국어에 맞게 fine-tuning 한 모델이라 한국어 검색 성능이 우수하다)
- 단점 : 모델 크기 커서 계산 리소스 많이 필요할 수 있다.
- 적용 시 고려사항
- 출력 임베딩 타원을 BGE-M3와 동일하게 768이다.
- 토크나이저는 해당 모델에 맞는 한국어 특화 토크나이저를 사용해야 한다.
- 모델 크기가 커서 GPU 메모리 요구량이 높다. batch size 조정을 통해 OOM 문제를 해결할 필요가 있다.
baai/bge-m3
- 장점 : MTEB 벤치마크에서 우수한 성능을 보여준 검증된 모델로. 대규모 데이터셋으로 학습되어 일반적인 지식 표현이 잘 된다.
- 단점 : 한국어만을 위한 최적화가 되어있지 않고 모델 크기가 크다.
- 적용 시 고려사항
- 출력 임베딩 차원은 768이며, 한국어 최적화가 되어있지 않아 도메인 특화 작업이 필요할 수 있다.
- BGE-M3의 토크나이저를 사용해야 하며, 한국어 텍스트 입력 시 성능 저하 가능성을 고려해야 한다.
- 모델 크기로 인해 계산 자원이 충분히 확보되어야 한다.
Solar Embedding-1-large
- 장점 : Upstage에서 개발한 최신 임베딩 모델로 한국어 처리 성능이 우수하다. MTEB 한국어 벤치마크에서 좋은 성능을 보였고 문장 임베딩에 특화되어 있어 검색 용도로 적합하다.
- 단점 : 대형 모델이라 계산 리소스가 많이 필요하고 최신모델이라 일부 도메인에서 검증 덜 되었을 수도 있다.
- 적용 시 고려사항
- 출력 임베딩 차원은 1024로, 다른 모델과 다를 수 있어 임베딩 크기에 맞춰 후처리 코드 조정이 필요하다.
- Solar 모델 전용 토크나이저를 사용해야 한다.
- 최신 모델이므로 도메인 적합성 검증이 필요하다.

조금 더 가벼운 모델
snunlp/KR-SBERT-V40K-klueNLI-augSTS (베이스라인 모델)
- 장점 : KLUE 데이터셋으로 학습되어 한국어 이해가 우수하다. NLI와 STS 태스크로 fine-tuning 되어 문장 간 의미 비교에 강점이 있다. 검색 시스템에 특화된 안정적이고 검증된 성능을 보인다.
- 단점 : 비교적 오래된 모델이라 최신 기술이 반영되지 않았다. 40K 크기의 어휘 사전은 현대의 대형 모델에 비해 제한적이다.
- 적용 시 고려사항
- 출력 임베딩 차원은 768이다.
- 토크나이저는 snunlp/KR-SBERT 전용 토크나이저를 사용해야 한다.
jhgan/ko-sroberta-multitask
- 장점 : 한국어에 특화된 RoBERTa 기반 모델이다. 비교적 가벼운 모델 크기로 계산 효율이 좋다. 문장 유사도, 텍스트 분류 등에서 안정적인 성능을 보인다.
- 단점 : 최신 대형 모델들에 비해 성능이 다소 떨어질 수 있다. 특정 도메인(예: 과학 기술)에 대한 특화된 학습이 되어있지 않다.
- 적용 시 고려사항
- 출력 임베딩 차원은 768로, 다른 RoBERTa 기반 모델과 호환된다.
- RoBERTa 전용 토크나이저를 사용해야 한다.
- 일부 태스크에서 추가적인 fine-tuning이 필요할 수 있다.
nlpai-lab/KoE5
- 장점 :E5 아키텍처를 한국어에 맞게 최적화하여 검색과 임베딩에 특화된 모델이다. 비교적 최근에 나온 모델이라 최신 기술이 반영되어 있고, 문장 임베딩에서 우수한 성능을 보인다.
- 단점 : 학습 데이터와 도메인이 다른 경우 성능 저하가 있을 수 있다. 검색에 특화되어 있어 범용성이 떨어질 수 있다.
- 적용 시 고려사항
- 출력 임베딩 차원은 768이며, E5 전용 토크나이저를 사용해야 한다.

이렇게 분석을 해봤고 실제로 우리가 사용한 임베딩 모델은 다음과 같다.
- snunlp/KR-SBERT-V40K-klueNLI-augSTS: 베이스라인 코드에서 적용돼서 기본 모델로 사용했다.
- dragonkue/bge-m3-ko: 베이스 라인에서 모델만 교체 후 점수 상승의 효과를 확인했다.


- jhgan/ko-sroberta-multitask: 기본 모델로 테스트 후 모델 교체 후 점수 상승의 효과를 확인했다.


그리고 시도했으나 못한 사용하지 못한 임베딩 모델은 다음과 같다.
- nlpai-lab/KoE5
- BAAI/bge-m3
- upstage/solar-embedding-1-large
사실 임베딩 모델을 분석하고 다르게 적용하는 걸 너무 늦게 (경진대회 제출 몇 시간 앞두고 알아챘다....) 알아차려서 빠르게 변경해 보고 제출해야 했던 상황이었다. 그리고 각 임베딩 모델마다 수정사항들이 필요하다는 것도 잘 몰랐다.
임베딩 모델 변경 시 공통적으로 수정해야 할 사항은 다음과 같다.
- 토크나이저: 모델마다 사용하는 토크나이저가 다르므로, Hugging Face의 AutoTokenizer를 사용해 해당 모델에 맞는 토크나이저를 로드해야 한다.
- 임베딩 차원: 모델마다 출력 임베딩 차원이 다를 수 있다. 예를 들어, Solar-Embedding-1-large는 1024차원이므로, 벡터 차원을 입력으로 사용하는 파이프라인에서 수정이 필요하다.
- 추론 속도와 메모리 최적화: 대형 모델을 사용할 경우 batch size와 max length를 조정하여 메모리 사용량을 줄여야 한다.
- fine-tuning: 도메인 특화 태스크에 대해 모델 성능이 부족할 경우, 추가적으로 fine-tuning을 고려해야 한다.
이렇게 모델 교체는 단순이 모델 이름을 변경하는 것만으로는 부족하며, 토크나이저, 임베딩 차원, 입력 데이터 처리 방식 등의 수정이 필요하다. 사용 사례와 계산 자원에 맞는 모델을 선택하고, 각 모델의 파라미터와 특징에 맞게 세부 설정을 조정해야 성능을 극대화할 수 있다.
그 외 QA 데이터셋 생성
임베딩 모델을 수정할 때 몇몇 모델은 QA(질문과 응답) 데이터셋으로 fine-tuning이 필수적인 모델이 있었다.
일반적으로 벡터 검색에 사용되는 모델은 사전 학습된 모델을 많이 사용한다. 이런 모델들은 주로 범용 임베딩(Universal Embedding)을 생성하도록 학습되었으며 특정 도메인이나 목적에 최적화되어 있지 않을 수 있다. QA 데이터셋을 이용해 Fine-tuning을 하면 모델이 주어진 문서 데이터의 콘텍스트에 맞는 임베딩을 생성할 수 있게 된다.
모델이 질문과 문서 간의 관계를 더 잘 이해하도록 만들기 위해서는, 단순히 문서를 벡터로 변환하는 것만으로는 부족하다.
QA 데이터셋은 질문(Question)과 그에 대한 적합한 답변(Positive Answer), 부적합한 답변(Negative Answer)을 제공함으로써 모델이:
- 유사도 평가 기준을 학습
- 질문 의도(Intent)와 답변 맥락(Context)을 이해하도록 도와준다.
💡 Negative Answer도 함께 생성한 이유는
모델이 “질문과 관련 없는 문서”를 효과적으로 구분하도록 도와주기 때문이다. 이는 벡터 검색에서 관련 없는 결과를 줄이는 데 중요한 역할을 한다.

일단 우리는 solar-pro를 이용해서 QA 데이터셋을 만들었는데 그렇게 좋은 데이터셋을 생성하지는 못했다...
그리고 임베딩 모델을 fine-tuning 하기까지 또 시간이 부족해서 결국 해당 QA 데이터는 사용하지 못했다.
4. Elastic Search 설정
Sparse Search에는 Elastic search를 사용했다. 여기서 ES에서 더 사용할 수 있는 옵션들 추가해서 문서 검색 최적화를 진행했다.
- Synonym_filter: 영어로 된 고유명사에 잘 대응하지 못하는 경우가 확인되어 Synonym Filter를 추가했다.
- similarity: 유사도 평가 알고리즘에는 텍스트에서 중요하지 않은 부분(노이즈)을 무시하고 중요한 패턴을 포착해서 더 정확한 검색 결과를 제공하는 것이 강점인 LMJelinekMercer 적용했다. (뉴스, 학술 검색 등에 많이 활용됨)

- boost: 추가된 메타데이터를 검색에 잘 활용하기 위해 boost를 설정했다. analyzer는 nori_with_synonyms을 활용했다.

5. Hybrid Search
검색엔진에서 문서를 추출할 때 sparse search와 dense search를 합친 하이브리드 서치를 활용했다.
Sparse, Dense Search 각각의 점수를 Normalized Score로 변환하고, 상대적으로 강한 확신을 보인 검색에 좀 더 많은 가중치를 부여하도록 설정했다. (둘 다 확신이 없는 경우는 Dense Search에 높은 가중치 부여)

처음에는 점수가 낮은 검색결과를 제외하도록 threshold를 적용했지만, 나중에 Reranker가 잘 작동하는 것을 확인한 뒤로는 threshold를 0으로 설정했다.
(사실 하이브리드 서치에서 검색한 결과의 순위를 매긴 것이, 리랭커에서 재정렬한 결과와 비교하면 큰 의미가 없었다. 왜냐하면 리랭커가 하이브리드 서치의 초기 점수를 보완하고 문서 순위를 더욱 정교하게 조정하는 역할을 효과적으로 수행했기 때문이다. 하이브리드 서치의 초기 결과는 관련 문서를 식별하는 데 사용되었고, 리랭커가 최종적으로 이를 정교하게 평가했기 때문에 순위 매김의 중요성이 상대적으로 줄어든 것으로 보였다...)
6. Re-Ranking
이전에 하이브리드 서치에서 더 파생되어서 어떻게 하면 더 적합한 문서를 추출해 내고 검색해 올 수 있을까 하다가 나온 방법이 Re-ranking이었다.
Re-ranking은 검색 시스템에서 초기 검색 결과를 재정렬하여 사용자 쿼리에 더 적합한 문서를 상위에 배치하는 과정이다. 일반적으로 검색 엔진의 초기는 빠르고 넓은 검색에 초점을 맞추고, Re-ranking은 이 초기 결과를 정교하게 평가해서 최적의 문서를 선택하는 정밀 단계를 수행한다.
Re-ranking 적용 과정은 다음과 같다.
- 초기 검색 단계:
Sparse와 Dense 검색을 결합한 하이브리드 서치를 통해 관련 문서를 추출한다. 이 단계에서는 많은 문서를 포함시키기 위해 상대적으로 낮은 threshold를 설정할 수 있다. - Re-ranking 모델 적용:
추출된 문서를 Re-ranking 모델에 입력으로 제공한다. 모델은 각 문서와 쿼리의 관련성을 평가하여 점수를 부여하고 순위를 조정한다. 점수는 모델의 아키텍처에 따라 학습된 가중치를 기반으로 계산된다. - 최종 문서 선정:
높은 점수를 받은 상위 문서를 사용자에게 제공한다. 필요시, 특정 문서를 제외하거나(never-answer) 반드시 포함하는(positive-answer) 전략도 함께 적용할 수 있다.
LLM 활용
그동안 우리가 프로젝트를 진행하면서 LLM을 많이 사용했고 또 성능이 좋게 나왔어서 리랭킹 과정에서도 LLM을 우선적으로 활용했다.

LLM을 Re-ranking에 활용할 수 있을 것으로 판단해서 적용한 결과 성능 향상이 있었지만, Re-ranking 모델에 비해서는 성능이 낮았다.
관련성에 따라 주어진 문서들을 재정렬하는 Task는 품질이 좋지 않았고, 가장 좋은 답변을 선택하거나, 완전히 관련이 없는 답변을 추출하는 Task는 상대적으로 잘 수행하는 것으로 확인했다.
- 장점: 특정 태스크(예: 관련 없는 답변 제외, 특정 답변 강조)에 강점을 가진다.
- 단점: 관련성 재정렬보다는 특정 문서 선택 또는 제외에 적합하다.
Re-ranking 모델 활용
LLM을 최대한 활용하고자 했지만 그럴듯한 성능 향상이 일어나지 않았다. 그러다가 리랭킹 모델이 따로 있다는 것을 찾게 되어서 reranking 모델을 사용했다.

Cross-Encoder 기반 모델
reranker = CrossEncoder("Dongjin-kr/ko-reranker")처럼 쿼리와 문서를 함께 입력으로 받아, 관련성을 평가하는 방식이다.
- 장점:
- 높은 성능과 정확한 관련성 평가.
- 단점:
- 계산 비용이 높아 대규모 문서 세트에는 부적합할 수 있다.
- 주요 활용:
- 초기 검색 결과가 적고 정밀한 평가가 필요한 경우.
Bi-Encoder 기반 모델 (우리는 적용하지 못한 모델이다.)
쿼리와 문서를 독립적으로 임베딩한 후, 벡터 간 유사도를 계산하는 방식이다.
- 장점:
- 계산 효율성이 높고 대규모 데이터 처리에 적합.
- 단점:
- Cross-Encoder에 비해 정밀도가 떨어질 수 있음.
- 주요 활용:
- 초기 검색 및 대규모 문서 필터링.
Re-ranking 모델도 다양하게 있지만 우리는 너무 뒤늦게 알았기 때문에 그중에서 좋은 평가를 받고 있는 모델을 적용했다. 그리고 성능이 크게 향상된 것을 확인했다. 그래서 최종적으로 선택된 방법은 Re-ranking 모델을 활용한 모델이었다.
7. 그 외 기타 여러 시도들
위에서 설명한 방법들 말고도 의미 기반 청킹, FAISS 벡터 DB 사용, 쿼리 다양화 들 다양한 시도들도 해봤지만 유의미한 성능 향상은 보이지 못했다.
의미 기반 청킹: 문서를 의미 기반 청킹 후 임베딩 진행.

Dense retrieve에서 Faiss 사용: 베이스라인 점수보다 낮아져서 이후로 엘라스틱서치로 돌아왔다.

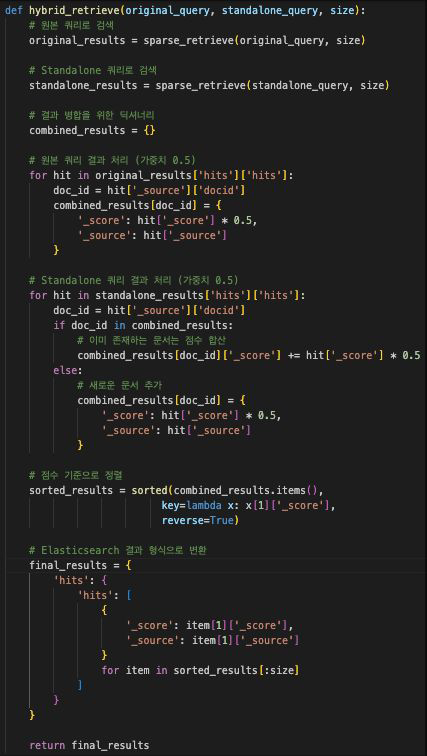
쿼리 다양화: Standalone_query와 원본 문제 그대로 던지는 original_query를 동시에 이용하면서 가중치 5:5로 검색하는 것이 가장 성능이 좋았다.
최종 결과
최종적으로 Public 기준 가장 높은 점수는
- jhgan/ko-sroberta-multitask
- Dongjin-kr/ko-reranker
를 적용한 방법이 제일 높게 나왔다.

그러나 private 기준 가장 높은 점수는
- jhgan/ko-sroberta-multitask
- Dongjin-kr/ko-reranker
- 검색 알고리즘 일부 개선 (candidate 확대 등)
를 적용한 방법이 제일 높게 나왔다.
최종 점수에 기여한 요소 중 하나는 초기 검색에서 candidate를 확대함으로써 Reranker가 더 정교하게 작동할 수 있도록 충분한 데이터를 제공한 점이다.

Lessons learned
- 이번 기회를 통해 간단하게라도 검색 + RAG를 구현할 수 있게 돼서 좋았다.
- 키워드를 먼저 다 만들어두고, standalone query도 다 만들어놓고, 불필요한 변수를 통제한 다음에 실험을 진행하는 것이 성능 향상 요인 파악에 중요하다는 것을 느꼈다.
- 외래어 이름, 학술 용어 등 고유명사 검색하는 방법 등 검색 구현 단계에서 실질적인 문제들을 좀 더 깊이 있게 학습하지 못한 게 아쉽다.
- 임베딩 모델을 변경하는 방법을 더 빨리 시도해 볼걸이라는 아쉬움이 매우 남는다.
- 검색 알고리즘을 다양하게 해보지 못해서 아쉽다.
최종 피드백
경진대회가 종료되고 각 팀이 발표를 진행하고 최종적으로 경진대회를 만드신 멘토분이 각 팀에 피드백을 진행해 주셨는데 우리 팀은 이런 피드백을 받았다.

일단 우리팀은 어떻게 하면 효율적으로 대회를 진행할까 고민해서 사실상 이번 경진대회는 Output csv에서 topk에 값이 있냐 없냐만 중요하고 실제로 LLM이 생성한 대답이 중요하진 않아서 (돈도 아낄 겸) 과학 질문인지 아닌지 판단하고 검색 엔진에서 문서만 검색하고 그 뒤에 진행되는 LLM API는 호출하지 않았다. 그리고 결국에 이번 경진대회에서는 검색엔진에서 해당 질문에 해당하는 문서를 찾아오는 게 관건이라 그 부분에 집중했던 거 같다.
그리고 다른 팀들의 발표도 듣고 보니 초반에 임베딩 모델을 변경해 보고, (dense search 적용도 대회 제출 전날에 적용해 봤으니,,) 이전 기수에서 최고성능이 나왔다는 BAAI/bge-m3 모델을 적용해 보면 그래도 성능이 더 올랐을 거라는 아쉬움이 남는다...
발표를 다 듣고 시도해보고 싶었던 방법: 청킹 Chunking
다른 팀 발표를 듣다 보니 다른 팀은 청킹을 잘 사용해서 성능 향상에 큰 도움을 받았다는 내용도 종종 나왔다.
청킹(Chunking)은 긴 문서를 여러 개의 작은 텍스트 조각(chunk)으로 나누는 작업을 의미한다. 특히 벡터 검색이나 자연어 처리에서 긴 문서를 처리할 때 자주 사용된다. 각 청크는 보통 독립적으로 처리될 수 있는 완전한 문장이거나 의미 단위로 구성되며, 검색, 임베딩 생성, 문서 매칭에 활용된다.
이번 경진대회는 과학 지문인 document를 임베딩하고 쿼리에 맞는 문서를 검색하는 태스크였다 보니 청킹이 꽤 중요했던 것 같았다.
청킹이 필요한 이유
- 모델 입력 길이 제한
NLP 모델(예: BERT, RoBERTa, GPT 등)은 입력 토큰 길이 제한이 있다. 보통 512~1024 토큰 길이로 제한되기 때문에 긴 문서를 한 번에 처리할 수 없다. 청킹은 긴 문서를 여러 조각으로 나누어 이 문제를 해결한다. (우리는 여기서 입력 토큰으로 standealone query를 사용했다고 보면 된다.)
- 의미 기반 검색 성능 향상
문서 전체를 하나의 임베딩으로 표현하면 세부 정보를 잃어버릴 수 있다. 문서를 의미 단위로 나누어 각각의 청크를 임베딩하면, 더 정밀하게 의미를 표현할 수 있다.
- 검색의 효율성
긴 문서보다 청크 된 문서는 검색 시스템에서 더 정밀하게 일치하는 내용을 찾을 수 있다. 특히 쿼리가 특정 문장이나 단락에 관련되어 있다면, 청킹이 도움이 된다.
- 문서의 특정 문장 강조
청크 단위로 의미를 분리하면 각 문장이 독립적인 문서로 취급될 수 있어 관련성이 높은 청크만 우선적으로 선택될 가능성이 높아진다.
청킹에서 고려해야 할 점
- 청킹 단위 크기
- 청크가 너무 작으면(예: 한 문장씩 나누기) 문서의 전체 맥락을 잃어버릴 수 있다.
- 청크가 너무 크면(예: 긴 단락) 의미를 구체적으로 포착하지 못할 수 있다.
- 일반적으로 200~300자 또는 2~3 문장 단위로 청킹 하는 것이 적절하다.
- 청크 간 연결성
- 청킹 된 텍스트는 독립적으로 처리되므로, 문서 간 맥락이 사라질 수 있다.
- 이를 해결하기 위해, 각 청크에 해당 문서의 제목, 키워드, 또는 문서 요약 등의 메타데이터를 추가할 수 있다.
- 예를 들어, 청크를 벡터화할 때 원래 문서의 정보(title, category 등)를 청크에 포함시켜 관련성을 유지한다.
- 과학 데이터 특성
- 과학 문서는 길이가 길고, 한 문서 안에 여러 개의 중요한 문장이 존재하기 때문에 청킹의 품질이 검색 성능에 직접적인 영향을 미친다.
- 따라서 청킹 전 문서 길이에 대한 EDA(탐색적 데이터 분석)를 통해 적절한 청킹 범위를 결정하는 것이 중요하다.
청킹의 적용 사례
- 벡터 검색(Vector Search)
- 청크 단위로 문서를 임베딩하여 검색 엔진에서 관련 청크를 반환하도록 설계한다.
- 검색 쿼리에 해당하는 청크를 반환하여 정확도를 높인다.
- RAG (Retrieval-Augmented Generation)
- RAG 모델에서 검색된 문서를 기반으로 답변을 생성할 때, 청크 단위로 검색된 정보를 결합하여 맥락 있는 응답을 생성한다.
- Dense Retrieval에서 효율화
- Dense 검색에서 각 청크를 임베딩으로 변환해 벡터화한다. 이때 청크 크기에 따라 검색 성능이 크게 달라질 수 있다.
다른 팀에서 발표한 내용을 기반으로 생각해 본 청킹의 중요성
- 과학 데이터에서의 청킹 중요성
- 과학 문서의 각 문장은 중요한 정보를 포함하며, 단순히 문서 전체를 임베딩으로 표현하면 이러한 세부 정보를 놓칠 수 있다.
- 시멘틱 청킹(의미 단위로 나누는 청킹)을 활용하면 과학 데이터의 문맥을 보존하면서도 검색 결과의 정확도를 높일 수 있다.
- 청킹 된 데이터에 메타데이터 추가
- 다른 팀이 제안한 것처럼 청킹된 각 단위에 원래 문서의 정보를 포함시키는 방식(예: 제목, 요약)을 사용하면, 맥락을 잃지 않으면서도 정확한 검색이 가능하다.
- 베이스라인 대비 성능 향상
- 단순히 전체 문서를 임베딩한 베이스라인보다, 청킹 후 시멘틱 기반으로 분리한 데이터에서 성능이 좋아졌다는 발표 내용은 검색 시스템에서 청킹의 효용성을 보여준다.
어떻게 시도했으면 더 나은 결과를 얻을 수 있었을까
- 문서 길이에 따른 청킹 전략 테스트
- 문서 길이를 분석하고, 최적의 청킹 범위를 결정했어야 한다. 예를 들어, 긴 문서와 짧은 문서에 동일한 청킹 크기를 적용하면 정보 손실이 발생할 수 있다.
- 시멘틱 청킹 적용
- 단순히 길이로 나누는 대신, 의미 단위로 나누는 알고리즘을 활용했으면 더 정밀한 청크가 생성되었을 가능성이 크다.
- 이를 위해 spaCy, NLTK, 또는 Hugging Face에서 제공하는 텍스트 분리 기능을 활용할 수 있다.
- 메타데이터 강화
- 청킹된 각 텍스트에 문서의 맥락(문서 제목, 카테고리, 키워드 등)을 메타데이터로 추가하면, 맥락 정보 손실 문제를 최소화할 수 있었다.
- 실험 기반 최적화
- 청킹 후 임베딩 생성과 검색 성능에 대한 다양한 실험을 통해 최적의 설정을 조기에 파악했어야 한다.
청킹은 긴 문서를 처리할 때 필수적인 작업으로, 특히 과학 데이터처럼 문맥이 중요한 데이터를 다룰 때 검색 및 임베딩 품질을 크게 향상시킬 수 있다. 다른 팀의 발표에서 확인된 사례처럼 시멘틱 청킹과 메타데이터를 강화하여 문맥을 유지했더라면, 검색 및 문서 순위화 단계에서 더 나은 성능을 얻었을 가능성이 크다.
최종적으로 청킹을 통한 검색 성능 개선을 초기에 더 많이 탐구하지 못한 점이 아쉬움으로 남는다.
'Upstage AI Lab 4기' 카테고리의 다른 글
| Upstage AI Lab 4기 AD 경진대회(화학 공정 이상 탐지) 후기 (0) | 2025.01.06 |
|---|---|
| Large Language Model 개요 (등장 배경 및 제작 프로세스) (1) | 2024.12.06 |
| Dialogue Summarization (일상 대화 요약) 경진대회 2주차 + 자체 평가 및 회고 (2) | 2024.12.01 |
| Dialogue Summarization (일상 대화 요약) 경진대회 1주차 (1) | 2024.11.28 |
| [CV 경진대회] 최종 제출, 자체 평가 및 회고 (1) | 2024.11.08 |