
📌 서론
지난 글에서 파인튜닝한 모델을 S3에 업로드하는 것까지 진행했었다. 이제는 S3에서 모델을 다운로드하고, FAST API를 이용해서 모델을 배포하는 과정을 진행해 보자! 그리고 도커로 build 해서 컨테이너형으로 배포까지 해보자!
이전글 링크:
TinyBERT로 감정 분석 모델 학습부터 AWS S3에 모델 업로드
📌 서론이번 글에서는 사전 학습된 모델(TinyBERT)을 허깅페이스에서 가져와서 IMDB 영화 리뷰 데이터셋으로 파인튜닝을 하고, 새로 학습된 모델을 AWS S3에 업로드하는 과정을 정리해볼것이다.IMDB
yijoon009.tistory.com
지금 진행할 프로젝트의 트리 구조는 다음과 같다.

FastAPI 적용
모델을 서빙하기 위해 Fast API를 적용해보자. app > app.py 파일을 만들어주고 다음과 같이 작성한다.
from fastapi import FastAPI
app = FastAPI()
@app.get('/')
def index():
return {'hello':'fastapi'}이렇게 만들어주고 실행해준다.
uvicorn app:app

이렇게 서버가 동작중인걸 확인할 수 있다.
S3에서 모델 다운
S3에서 모델을 다운로드할 모듈을 만들어보자. app > scripts > s3.py 파일로 만들어준다.
- model_name: 지난 글에서 s3 버킷에서 model name에 해당하는 폴더를 만들고 그 안에 모델 파일을 만들어줬기 때문에 이번에도 model name을 받을 것이다.
- local_path: 현재 로컬 저장소에 모델을 저장할 위치다.
import boto3
import os
s3 = boto3.client('s3')
def download_dir(bucket_name, model_name, local_path):
"""
S3에서 주어진 모델 이름의 파일들을 로컬 경로로 다운로드하는 함수.
버킷 안에 있는 폴더 구조를 유지하며 다운로드함.
Parameters:
- bucket_name: S3 버킷 이름
- model_name: S3 내에서 모델 파일이 저장된 폴더 이름 (prefix)
- local_path: 파일을 저장할 로컬 경로
"""
s3_prefix = f'{model_name}/'
os.makedirs(local_path, exist_ok=True)
# Paginator를 사용하여 모든 파일 목록 가져오기
paginator = s3.get_paginator('list_objects_v2')
for result in paginator.paginate(Bucket=bucket_name, Prefix=s3_prefix):
if 'Contents' in result:
for key in result['Contents']:
s3_key = key['Key']
# 파일이 실제로 존재하는지 확인 (디렉토리 제외)
if not s3_key.endswith('/'):
# 로컬 파일 경로 설정
relative_path = os.path.relpath(s3_key, s3_prefix)
local_file = os.path.join(local_path, relative_path)
# 디렉토리 먼저 생성
os.makedirs(os.path.dirname(local_file), exist_ok=True)
# 파일 다운로드
print(f'Downloading {s3_key} to {local_file}...')
s3.download_file(bucket_name, s3_key, local_file)
print('모델 다운로드 완료')- if 'Contents' in result: S3에서 가져온 결과 result는 각 페이지의 파일 목록과 관련된 데이터를 담고 있다. result 딕셔너리 안에 Contents라는 키가 있을 경우, 해당 키는 실제로 S3 버킷 안에 있는 파일들의 정보를 담고 있다. 따라서 해당 조건문을 통해 result에 파일이 존재하는지 확인한다.
- for key in result['Contents']: result['Contents']는 S3에 저장된 파일 목록을 담고 있는 리스트다. 각 파일에 대한 정보가 딕셔너리 형태로 저장되어 있다. 그래서 이 부분에서는 result['Contents'] 리스트 안의 각 파일 정보를 key라는 변수로 하나씩 가져오는 반복문을 돌리고 있다.
- s3_key = key['Key']: 각 파일 정보는 key라는 딕셔너리로 되어 있고, 이 딕셔너리 안에서 'Key'라는 필드는 해당 파일의 경로를 나타낸다. 예를 들어, S3에서 tinybert-sentiment-analysis/config.json 같은 파일의 전체 경로가 'Key' 값으로 들어 있다. 그래서 s3_key = key['Key']는 각 파일의 경로를 가져와서 s3_key에 저장한다.
만약에 S3 버킷 안에
tinybert-sentiment-analysis/config.json
tinybert-sentiment-analysis/model.safetensors
tinybert-sentiment-analysis/tokenizer_config.json이런 파일들이 들어있다고 가정해 보면,
result['Contents']에는 다음과 같은 값이 들어있다.
result['Contents'] = [
{'Key': 'tinybert-sentiment-analysis/config.json'},
{'Key': 'tinybert-sentiment-analysis/model.safetensors'},
{'Key': 'tinybert-sentiment-analysis/tokenizer_config.json'}
]relative_path 변수
- os.path.relpath(s3_key, s3_prefix)는 s3_key에서 s3_prefix를 제거한 상대 경로를 반환한다.
- s3_key가 tinybert-sentiment-analysis/config.json이라면,
- relative_path는 config.json이 된다.
- 이렇게 하면 로컬 파일 경로를 지정할 때 불필요하게 전체 S3 경로를 사용하지 않고, 폴더 구조만 남기고 파일 이름만 상대 경로로 남기게 된다.
app.py에서 모델 다운로드
위에서 만든 함수를 실제로 사용해 보자. 아까 만든 app.py에 모델을 다운받아주는 코드를 추가해 주자.
from scripts import s3
import torch
from transformers import pipeline
# Set device for model inference
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# Configuration for model download and loading
model_name = 'tinybert-sentiment-analysis'
local_path = f'ml-models/{model_name}'
bucket_name = 'my-mlops'
# Function to download model from S3 if necessary
def ensure_model_download(bucket_name, model_name, local_path, force_download=False):
if not os.path.isdir(local_path) or force_download: # 모델 폴더가 없거나 강제 다운로드일 경우만
s3.download_dir(bucket_name, model_name, local_path)
# Ensure the model is downloaded and load it into the pipeline
ensure_model_download(bucket_name, model_name, local_path)
sentiment_model = pipeline('text-classification', model=local_path, device=device)이렇게 코드를 추가해 주고 다시 서버를 실행해 주면 다음과 같이 모델이 잘 다운받아졌다.


모델 적용 API 생성
이제 실제로 다운받은 모델을 사용해 보는 uri를 뚫어주자.
그전에 app > scripts > data_model.py로 모델의 input, output 타입을 제한해 주는 코드를 작성해 주자.
from pydantic import BaseModel
class BertInput(BaseModel):
text: list[str]
class BertOutput(BaseModel):
model_name:str
text: list[str]
labels: list[str]
scores: list[float]
prediction_time: int # 초 데이터- BertInput과 BertOutput 클래스는 API에서 들어오는 요청 데이터와 나가는 응답 데이터의 구조를 명확하게 제한해 주는 역할을 해줘서 데이터 유효성 검사를 쉽게 할 수 있다.
- 예를 들어, 리스트가 아닌 단일 텍스트를 보내도 Pydantic의 주요 기능 중 하나인 "자동 변환"을 통해 자동으로 리스트로 변환되기 때문에 더 유용하다.
이제 맵핑을 만들어주자.
@app.post('/api/v1/sentiment')
def sentiment_analysis(data: BertInput):
start_time = time.time()
output = sentiment_model(data.text) # 모델의 결과이 부분에서 /api/v1/sentiment로 POST 요청이 들어오면, BertInput 형태의 데이터를 받아서 처리하게 된다. 여기서 sentiment_model(data.text)는 사전 학습된 감정 분석 모델을 사용하여 입력된 텍스트에 대한 결과를 출력하는 부분이다.
모델의 출력은 보통 감정에 대한 레이블(예: 긍정, 부정)과 그에 따른 점수(확률 값)로 반환된다.
labels = [x['label'] for x in output]
scores = [x['score'] for x in output]
end_time = time.time()
prediction_time = int((end_time - start_time)*1000) # 초 단위모델의 결과에서 각 텍스트에 대한 label과 score를 추출해 리스트로 저장한다. 예를 들어, output이 여러 감정 분석 결과를 포함하고 있다면 각각의 label과 score를 따로 리스트로 만들어서 저장한다.
result = BertOutput(
model_name='tinybert-sentiment-analysis',
text=data.text,
labels=labels,
scores=scores,
prediction_time=prediction_time
)
return result모델의 예측 결과와 요청 데이터를 기반으로 BertOutput 형식에 맞게 결과를 반환한다. 반환되는 결과는 아래와 같은 구조를 따르게 된다:
{
"model_name": "tinybert-sentiment-analysis",
"text": ["example text"],
"labels": ["positive"],
"scores": [0.95],
"prediction_time": 120
}이렇게 구조화된 JSON 데이터를 반환함으로써 클라이언트는 API가 예측한 감정 결과와 모델의 처리 속도를 확인할 수 있게 된다.
이렇게 맵핑을 만들어주고 다시 서버를 재실행해주면 된다!
모델 테스트 1 - Swagger UI 활용
브라우저로 열고 경로 뒤에 /docs를 붙이면 테스트할 수있는 ui가 제공된다!
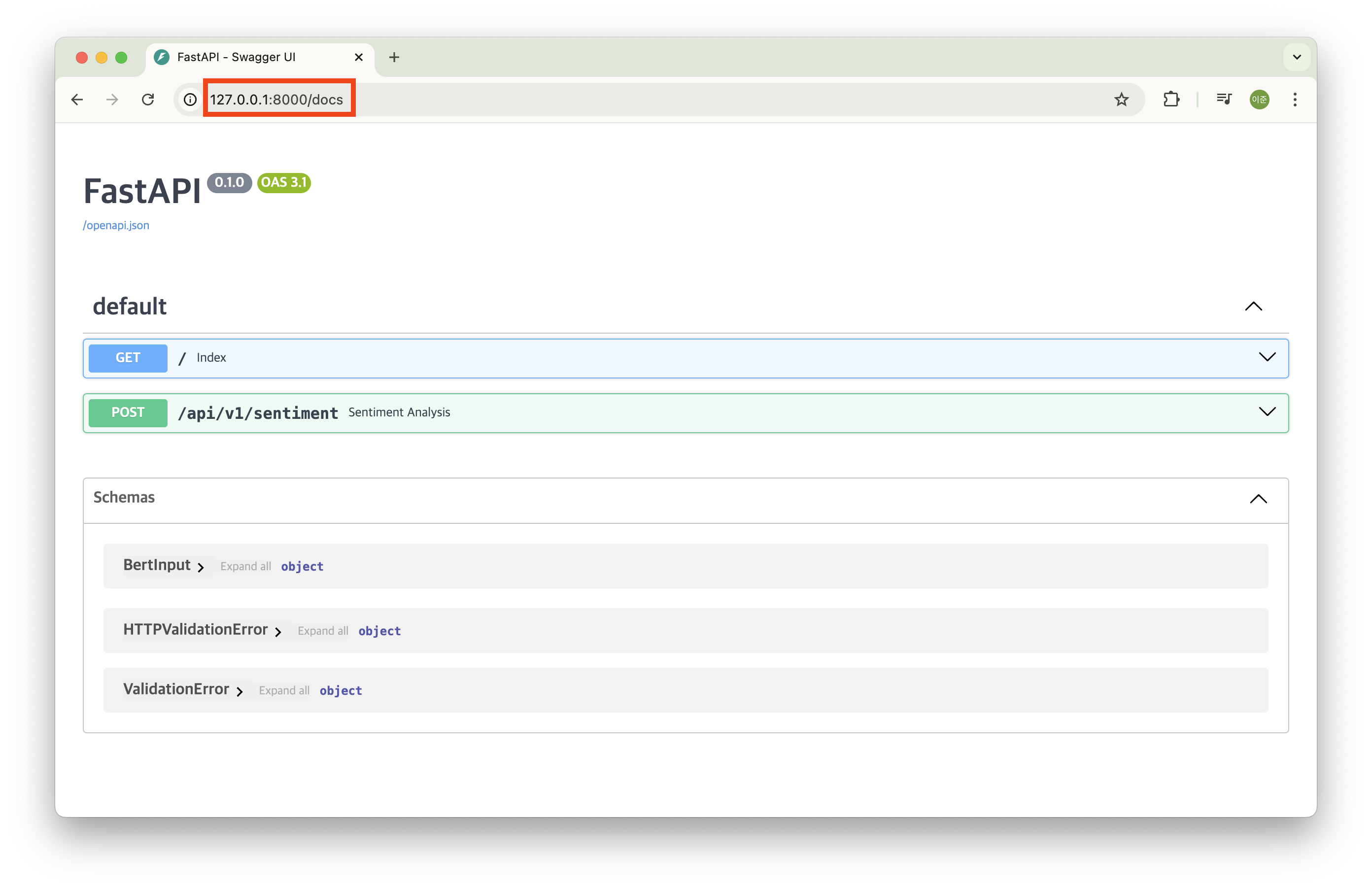
위 화면에서 해당 맵핑을 클릭하고 'Try it out' 버튼을 클릭하면 테스트할수 있는 화면이 나온다.

바뀐 화면에서 테스트해보고 싶은 리뷰를 적고 Execute 버튼을 누르면 아래 결과로 모델의 응답값을 확인할 수 있다.
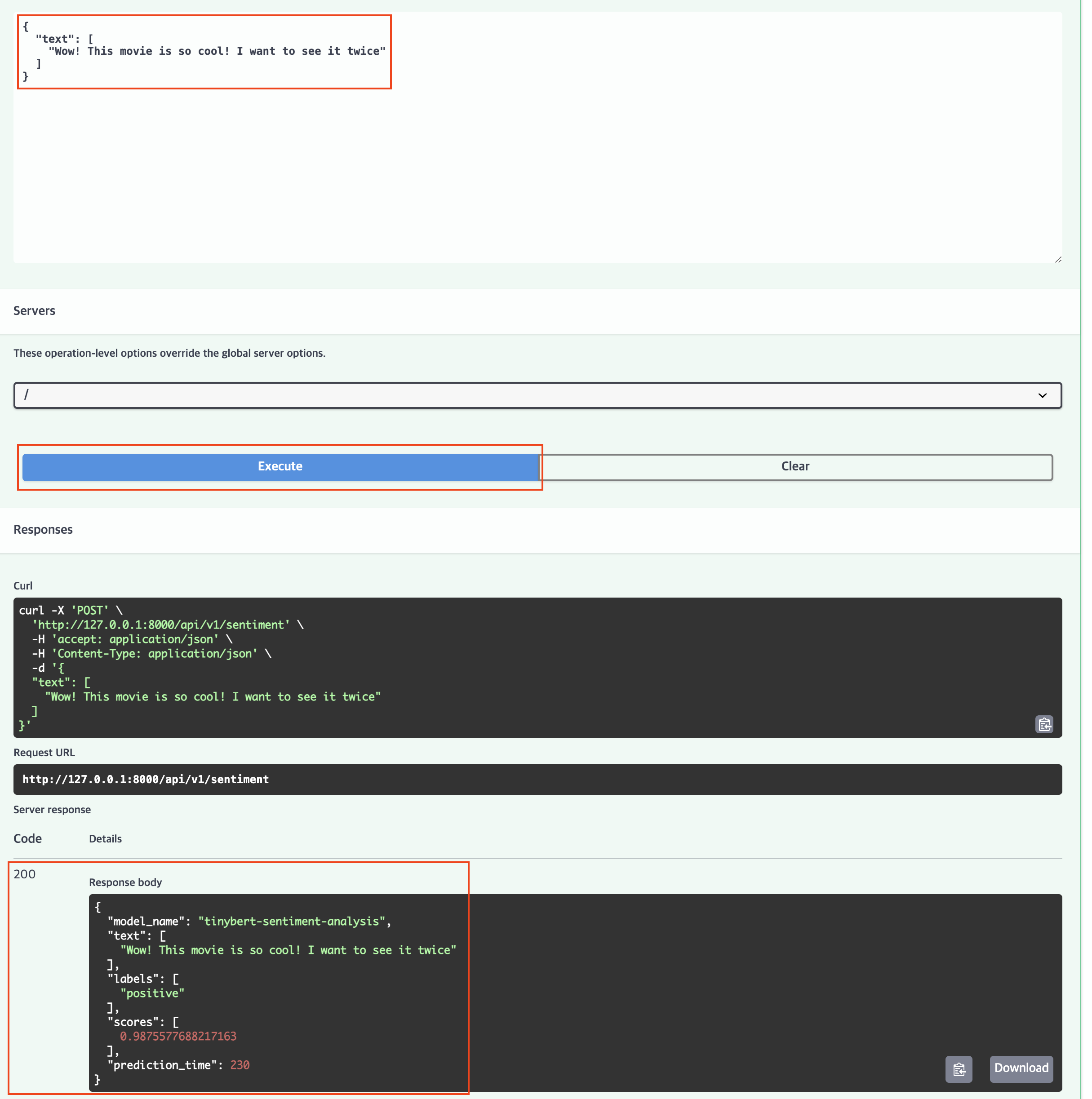
긍정 98퍼로 잘 맞춘 걸 확인할 수 있다.
모델 테스트 2 - Thunder Client 활용
Swagger UI 말고 이전에 사용해 본 Thunder Client로도 테스트해 볼 수 있다.
이렇게 uri를 입력해 주고, 원하는 리뷰를 작성하고 'Send' 버튼을 클릭하면 우측에 모델의 응답값을 확인할 수 있다.

모델 테스트 3 - streamlit 활용
이 외에도 streamlit을 활용해서도 시각적으로 페이지를 확인해 볼 수 있다.
front_streamlit.py 파일로 만들어줬는데 이 파일을 실행하기 전에 동일 경로에 아까 다운로드한 ml-models 폴더를 app 폴더 바깥으로 복사(이동)해줘야 한다. (아니면 해당 파일을 app 폴더 내부에서 만들어주면 그대로 사용해도 된다.)
import streamlit as st # MVP
st.title("TinyBERT Model Test Web")
st.header("Check your sentiment")
text = st.text_area("게시글 내용을 입력해주세요", "게시글 내용")
clicked = st.button("확인")
import torch
from transformers import pipeline
device = torch.device('cuda') if torch.cuda.is_available() else torch.device("cpu")
classifier = pipeline('text-classification',
model='ml-models/tinybert-sentiment-analysis', device=device)
if clicked:
with st.spinner("Loading..."): # mlflow
res = classifier(text)
st.write(res)이렇게 만들어주고 실행 명령어는 다음과 같다.
python -m streamlit run front_streamlit.py그럼 이렇게 화면이 뜬다. 여기서 내용을 작성하고 확인 버튼을 클릭하면 똑같이 모델의 응답값을 확인할 수 있다.

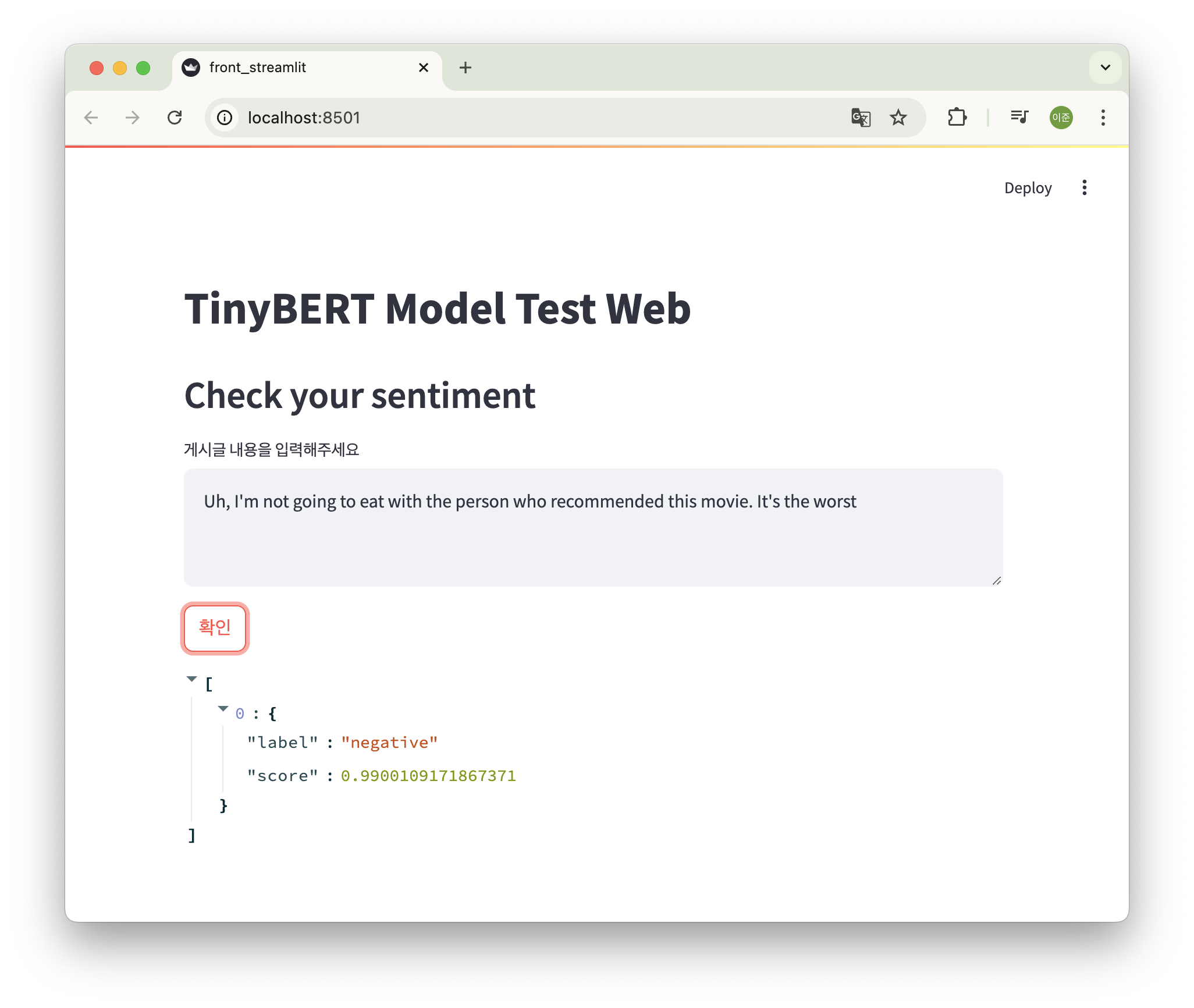
도커 생성
이제 이 환경을 도커로 빌드해서 배포를 해보자.
(해당 코드를 진행하기 전에 docker desktop을 설치하면 조금 더 편하게 확인할 수 있다.)
Dockerfile을 만들기 전에 해당 프로젝트에 사용된 라이브러리들을 정리한 requirements.txt 파일을 만들어주자.
app 디렉토리 안에서 다음 명령어를 실행하면 자동으로 requirements.txt 파일이 생성된다.
pip freeze > requirements.txtDockerfile
Dockerfile은 도커 이미지(운영 체제, 애플리케이션, 필요한 종속성 등을 포함하는 패키지)를 어떻게 만들지 정의한 파일이다. 이 파일에서 지정한 단계에 따라 도커 이미지를 생성하게 된다.
FROM python:3.10-slim
# 필수 패키지 설치
RUN apt-get update && apt-get install -y \
build-essential \
pkg-config \
libhdf5-dev \
curl
WORKDIR /app
COPY ./app/requirements.txt /app/
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
COPY ./app /app
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "5000"]- 베이스 이미지 선택: FROM python:3.10-slim은 기본적으로 Python 3.10을 실행하는 경량의 Linux 이미지를 사용하도록 지정한다.
- 필수 패키지 설치: apt-get을 사용해 필요한 시스템 패키지를 설치한다.
- 작업 디렉토리 설정: WORKDIR /app으로 /app 디렉토리를 작업 디렉토리로 설정한다.
- 의존성 설치: pip install을 통해 requirements.txt에 있는 파이썬 패키지들을 설치한다.
- 애플리케이션 복사: COPY 명령어로 앱 소스 코드를 이미지 내부로 복사한다.
- CMD: 컨테이너 실행 시 기본적으로 FastAPI 애플리케이션을 실행하는 명령어를 지정한다.
docker-compose.yml
docker-compose.yml은 여러 개의 Docker 컨테이너를 동시에 구성하고 실행하기 위한 파일이다. 이 파일을 사용하면 각각의 컨테이너를 개별적으로 설정하고 관리할 필요 없이 한 번에 컨테이너를 실행할 수 있다.
services:
app: # FastAPI/ 컨테이너 1
build:
context: .
ports:
- ":5000"
- 서비스 정의: services 아래에 FastAPI 애플리케이션을 실행하는 컨테이너를 정의한다.
- 이미지 빌드: build 키워드를 사용하여 Dockerfile을 기반으로 이미지를 빌드하도록 지정한다. 여기서 context: .은 현재 디렉토리(즉, docker-compose.yml 파일이 위치한 디렉토리)에서 Dockerfile을 찾아 이미지를 빌드한다는 의미이다.
- 포트 매핑: ports 설정을 통해 로컬 호스트와 컨테이너의 포트를 연결한다. 예를 들어, ":5000"은 로컬 머신의 임의의 포트와 컨테이너의 5000번 포트를 매핑하여 FastAPI 애플리케이션에 접근할 수 있도록 한다.
이렇게 만들어주고 docker를 빌드해 보자.
docker-compose.yml 파일이 있는 경로에서 다음 명령어를 실행해 주자. (난 200초 정도 걸렸던 것 같다.)
docker-compose build
docker-compose build 명령어를 실행하면 build 섹션에서 지정한 Dockerfile이 실행된다. 즉, docker-compose.yml 파일에서 이미지를 빌드할 때, 내부적으로 Dockerfile이 실행되어 도커 이미지를 생성하게 된다. docker-compose는 Dockerfile을 호출해 이미지를 빌드하고 컨테이너를 실행하는 역할을 한다.
이제 컨테이너를 띄워보자!
docker-compose up
위 명령어를 실행하면 도커 컨테이너가 실행된걸 확인할 수 있다.

이렇게 도커 컨테이너까지 실행해 봤다. 이 이후에 nginx를 이용해서 조금 더 완성도 높게 모델을 서빙하고 배포해 보는 과정을 진행해 봐야겠다. nginx와 FastAPI를 협업해서 nginx를 리버스 프록시로 사용해서 성능 향상이라던가, 보안 측면에서도 이점이 있는데 아직 nginx까지는 ,,, 조금 어렵다.. 그리고 Airflow도 도입할 것 같은데 너무 어려우면,,, 정리는 못할 수도 있지만 최대한 적용해서 정리까지 해봐야겠다!!
'MLOps' 카테고리의 다른 글
| Docker 기반 Airflow, MLFlow, FastAPI, Streamlit 적용한 MLOps 프로젝트 후기 (5) | 2024.10.12 |
|---|---|
| Docker로 mlflow 실행할때 OSError: [Errno 30] Read-only file system: '/mlflow' 에러 발생 (5) | 2024.10.09 |
| Docker 환경에서 Airflow의 DAGs 테스트 (파이썬 코드, Slack Webhook, MLFlow) (4) | 2024.09.26 |
| TinyBERT로 감정 분석 모델 학습부터 AWS S3에 모델 업로드 (3) | 2024.09.23 |
| MLFlow로 머신러닝 모델 실험 관리 및 Tag로 stage 표시 (3) | 2024.09.22 |