
코틀린과 스프링 부트 3에서 DynamoDB 항목 추가하기

📌 서론
이전 글에서 DynamoDB에 테이블을 생성했고 항목을 추가해 봤다. 이제 스프링 부트에서 DynamoDB를 연동해서 스프링 부트 코드에서 DynamoDB 테이블에 항목을 추가해 보자
dependencies 추가
코틀린과 DynamoDB와 연동하려면 일단 디펜던시가 필요하다.
나는 아래 링크에서 디펜던시를 가져왔다.
https://central.sonatype.com/artifact/aws.sdk.kotlin/dynamodb
Maven Central: aws.sdk.kotlin:dynamodb
Discover dynamodb in the aws.sdk.kotlin namespace. Explore metadata, contributors, the Maven POM file, and more.
central.sonatype.com
위 링크는 Sonatype Central에서 제공하는 AWS SDK for Kotlin의 DynamoDB 모듈에 대한 페이지다. Maven Repository와 Sonatype Central은 비슷한 역할을 한다고 볼 수 있다. 두 서비스 모두 Java VM 언어(Java, Kotlin, Scala 등)를 위한 라이브러리와 프레임워크의 중앙 집중식 저장소 역할을 한다.
2024년 2월 기준 아래 디펜던시를 추가해 줬다.
dependencies {
implementation("aws.sdk.kotlin:dynamodb:1.0.64")
}
DynamoDBConfig - DynamoDB 클라이언트 Bean 등록
먼저, DynamoDbClient를 Spring Bean으로 등록하기 위한 설정 클래스를 생성한다. 이 클래스는 DynamoDB 클라이언트 인스턴스를 애플리케이션의 다른 부분에서 주입받아 사용할 수 있도록 해준다.
import aws.sdk.kotlin.services.dynamodb.DynamoDbClient
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
@Configuration
class DynamoDBConfig {
@Bean
fun dynamoDbClient(): DynamoDbClient {
return DynamoDbClient { region = "ap-northeast-2" } // AWS 리전 설정
}
}
DynamoDBService - 항목(item) 추가 로직을 포함하는 서비스 클래스
다음으로, DynamoDB에 데이터를 추가하는 로직을 담당할 DynamoDBService 클래스를 생성한다. 이 클래스는 DynamoDbClient Bean을 주입받아 사용한다.
import aws.sdk.kotlin.services.dynamodb.DynamoDbClient
import aws.sdk.kotlin.services.dynamodb.model.AttributeValue
import aws.sdk.kotlin.services.dynamodb.model.PutItemRequest
import org.recipia.alarm.logger
import org.springframework.stereotype.Service
@Service
class DynamoDBService (
private val dynamoDbClient: DynamoDbClient
) {
val log = logger()
/**
* DynamoDB에 닉네임 정보를 추가하는 메소드
*/
suspend fun addNicknameToDB(memberId: Long, nickname: String, retryCount: Int = 0) {
val itemValues = mapOf(
"memberId" to AttributeValue.N(memberId.toString()),
"nickname" to AttributeValue.S(nickname)
)
val putItemRequest = PutItemRequest {
tableName = "member_nickname"
item = itemValues
}
try {
dynamoDbClient.putItem(putItemRequest)
log.info("닉네임 정보 DynamoDB에 추가 성공: $memberId, $nickname")
} catch (e: Exception) {
log.warn("DynamoDB에 닉네임 정보 추가 실패: ${e.message}")
if (retryCount < 2) { // 최초 시도 후 실패하면 2번 더 재시도하도록 수정
log.warn("닉네임 정보 DynamoDB에 저장 재시도 중... (재시도 횟수: ${retryCount + 1})")
addNicknameToDB(memberId, nickname, retryCount + 1)
} else {
log.error("닉네임 정보 DynamoDB에 저장 최종 실패: $memberId, $nickname")
}
}
}
}
이 코드를 이해하기 위해선 일단 코루틴과 suspend 개념을 좀 이해해야 한다. 코루틴과 suspend에 대한 개념은 다음 링크에서 자세하게 설명되어 있다.
코루틴과 suspend로 간단한 비동기 처리
코루틴과 suspend로 간단한 비동기 처리 📌 서론 이 글에서는 코루틴과 suspend 함수를 사용하여 복잡한 비동기 작업을 간단하게 처리하는 방법을 정리해보려고 한다. 코루틴(Coroutines) 기본 코루틴
yijoon009.tistory.com
addNicknameToDB 메서드를 suspend 함수로 선언한 이유
우선 DynampDB에 데이터를 추가하는 메서드인 dynamoDbClient.putItem을 클릭해서 들어가 보자.
들어가면 다음과 같이 putItem 메서드가 선언되어 있다. 이 코드는 AWS SDK에서 제공해 주는 코드다.
public abstract suspend fun putItem(input: aws.sdk.kotlin.services.dynamodb.model.PutItemRequest): aws.sdk.kotlin.services.dynamodb.model.PutItemResponse
putItem 함수에 suspend 키워드가 사용된다는 것은 해당 함수가 코루틴 내에서 비동기적으로 실행될 수 있음을 의미한다. 코루틴을 사용하면 함수의 실행을 일시 중단할 수 있어, 비동기 작업을 효율적으로 관리할 수 있다. 이러한 특성 때문에, putItem을 호출하는 addNicknameToDB 메서드 역시 suspend로 선언되어야 한다. 이는 addNicknameToDB가 비동기 작업을 수행하는 dynamoDbClient.putItem을 호출하기 때문이다.
결론적으로, suspend 키워드는 해당 함수가 코루틴 내에서만 호출될 수 있게 하며, 비동기 작업을 수행하는 함수를 호출할 경우, 그 호출자 함수도 suspend로 선언해야 한다. 이를 통해 코루틴의 비동기 실행 컨텍스트 내에서 작업의 완료를 기다릴 수 있다.
사실 suspend로 선언하는 것 말고 GlobalScope.launch를 사용하는 방법도 있긴 하다.
- 비동기 실행: GlobalScope.launch는 새로운 코루틴을 글로벌 스코프에서 시작한다. 이는 해당 코루틴이 애플리케이션의 생명 주기와 독립적으로 실행됨을 의미한다. 즉, 호출한 콘텍스트와 무관하게 작업이 백그라운드에서 진행된다.
- 코루틴 스코프: GlobalScope는 애플리케이션 전역에서 실행되는 코루틴의 생명 주기를 관리한다. 하지만 이 스코프를 사용하면 생성된 코루틴이 애플리케이션의 다른 부분과 생명 주기를 공유하지 않기 때문에, 애플리케이션 종료 시점에 아직 완료되지 않은 코루틴이 있어도 애플리케이션은 종료될 수 있다.
예를 들어서 이런 식으로 addNicknameToDB 메서드에서 suspend 키워드를 제거하고 putItem을 사용하는 부분에서만 코루틴을 적용시키는 방법도 존재한다.

이렇게 처리했을 때 다음과 같은 에러사항이 발생한다.
- 에러 처리: 현재 방식에서는 GlobalScope.launch 내부에서 발생하는 예외를 try-catch 블록이 잡지 못한다. 왜냐하면 launch는 비동기적으로 코드 블록을 실행하기 때문에, 예외가 발생해도 launch를 호출한 스코프로 전파되지 않는다.
- 결과 처리: GlobalScope.launch는 코루틴이 완료되기를 기다리지 않는다. 따라서 putItem 호출이 성공적으로 완료되었는지 확인하기 전에 무조건 "닉네임 정보 DynamoDB에 추가 성공" 메시지가 출력된다. 실제로는 putItem 호출의 성공 여부와 관계없이 메시지가 출력된다는 뜻이다.
이런 에러사항이 있기 때문에 GlobalScope 대신, 함수를 호출하는 컨텍스트에 더 적합한 코루틴 스코프를 사용하는 것이 좋다. 예를 들어, 스프링 애플리케이션의 컴포넌트 내에서 코루틴을 시작할 경우, 해당 컴포넌트의 생명 주기와 연결된 코루틴 스코프를 사용할 수 있다.
그래서 putItem을 호출하는 메서드에 GlobalScope.launch를 사용하지 않고 suspend 키워드를 사용한 것이다.
☝️ 잠깐! suspend를 사용하면 비동기로 진행될 텐데 try-catch에서 에러가 잡힐까?
suspend 함수를 사용할 때의 예외 처리에 대해 몇 가지 중요한 점을 짚어보자.
suspend 키워드가 붙은 함수는 코루틴 내에서 실행되며, 이는 비동기 작업을 "일시 중단"할 수 있고, 작업이 완료될 때까지 코드의 실행을 기다리게 할 수 있다는 것을 의미한다. 이러한 특성 덕분에, suspend 함수 내부에서 발생하는 예외는 동기 코드를 작성할 때와 유사하게 try-catch 블록을 사용하여 처리할 수 있다.
비동기 함수에서의 예외 처리
- suspend 함수와 예외 처리: suspend 함수 내에서 발생한 예외는 호출한 코루틴 내에서 try-catch 블록을 사용하여 직접적으로 처리할 수 있다. 이는 suspend 함수가 코루틴의 일시 중단 기능을 사용해 비동기 작업을 동기적인 방식으로 표현할 수 있게 해 주기 때문이다.
- 응답 기다림: suspend 함수를 호출하는 동안, 코루틴은 해당 함수가 완료될 때까지 실행을 일시 중단한다. 따라서 dynamoDbClient.putItem(putItemRequest) 같은 suspend 함수의 결과(또는 예외)를 호출한 코드에서 직접 처리할 수 있다.
즉, suspend 함수로 선언한 코드는 dynamoDbClient.putItem을 직접 호출하고 있으므로, 이 함수에서 발생하는 예외는 try-catch 블록으로 잡을 수 있다.
🤔 그럼 여기서 'addNicknameToDB 메서드도 suspend를 사용했으니까 이 메서드를 사용하는 곳도 suspend 키워드를 사용해야 하지 않나?'라는 의문이 들 수도 있다. 이 부분에 대해서는 아래에서 마저 설명하겠다.
mapOf와 to 키워드
mapOf는 Kotlin의 표준 라이브러리 함수로, 키-값 쌍을 포함하는 읽기 전용 Map을 생성한다.
여기서 사용된 "memberId" to AttributeValue.N(memberId.toString())는 키 "memberId"와 값 AttributeValue.N(memberId.toString())의 쌍을 만든다. to는 Kotlin에서 중위 호출(infix call)을 사용하는 특별한 함수로, 두 개의 항목을 하나의 Pair로 묶는다. 즉, a to b는 Pair(a, b)와 동일하며, 이는 Map의 항목을 초기화할 때 사용된다.
AttributeValue.N과 AttributeValue.S
AttributeValue 클래스는 AWS SDK for Kotlin에서 DynamoDB 항목의 속성 값을 나타내는 데 사용된다. N과 S는 각각 Number와 String 타입의 속성 값을 나타내는 메서드이다.
- AttributeValue.N(String)은 숫자 타입의 속성 값으로, DynamoDB에서 숫자를 나타낼 때 사용된다. 여기서 memberId.toString()은 memberId (Long 타입)를 String으로 변환하여 숫자 타입의 값으로 처리한다.
- AttributeValue.S(String)은 문자열 타입의 속성 값으로, DynamoDB에서 문자열을 나타낼 때 사용된다.
try와 catch
try와 catch 블록은 예외 처리를 위해 사용된다. dynamoDbClient.putItem(putItemRequest) 호출은 네트워크 요청을 포함하고 있으며, 실행 중 다양한 예외가 발생할 수 있다 (예: 네트워크 문제, 잘못된 요청 형식, 권한 문제 등). try 블록 안에서 해당 코드를 실행하고, 예외가 발생하면 catch 블록이 해당 예외를 처리한다. 이 방식을 통해 프로그램이 예외 상황에서 안정적으로 동작하도록 할 수 있다.
DynamoDB에 데이터 추가 실패 시 재시도
DB에 데이터 추가에 실패했을 때 재시도 로직은 다음과 같다.
1. 첫 시도: addNicknameToDB 메서드가 호출되어 DynamoDB에 사용자의 memberId와 nickname을 추가하려고 시도한다. 이때 retryCount는 기본값 0으로 시작한다.
2. 성공 시: 데이터 추가가 성공하면, 성공 로그를 남기고 작업을 종료한다.
3. 첫 번째 실패 시: 데이터 추가가 실패하고 예외가 발생하면, 실패 로그를 남긴다. 이때 retryCount가 2 미만인 경우, 즉 아직 재시도할 기회가 2번 남아있는 경우, 재시도 로그를 남기고 retryCount를 1 증가시킨 후 재귀 호출을 통해 메서드를 다시 실행한다.
4. 재시도 로직:
- 첫 번째 재시도 (retryCount = 1) 실패 시, retryCount가 여전히 2 미만이므로, 다시 한번 재시도할 수 있다. retryCount를 증가시키고 메서드를 다시 호출한다.
- 두 번째 재시도 (retryCount = 2) 실패 시, retryCount가 2 미만이 아니므로, 재시도를 하지 않고 최종 실패 로그를 남긴 후 작업을 종료한다.
즉, addNicknameToDB 메서드는 최초 시도 포함 총 3번의 시도(첫 시도 + 2번의 재시도)가 가능하다. 첫 시도 후 실패할 경우, 최대 2번까지 재시도를 시도하며, 각 시도 후에는 retryCount를 체크하여 추가 재시도 여부를 결정한다. 이 과정은 일시적인 오류에 대응하여 데이터 추가 성공 확률을 높이기 위한 것이다.
DynamoDBEventListener - DynamoDBService를 사용하는 클래스
이 클래스는 DynamoDBService에서 선언한 addNicknameToDB 메서드를 호출하는 클래스다.
import kotlinx.coroutines.launch
import kotlinx.coroutines.CoroutineScope
import kotlinx.coroutines.Dispatchers
import org.springframework.stereotype.Component
import org.springframework.context.event.EventListener
@Component
class DynamoDBEventListener(private val dynamoDBService: DynamoDBService) : CoroutineScope by CoroutineScope(Dispatchers.IO) {
@EventListener
fun insertNicknameToDynamoDB(event: FeignNicknameSpringEvent) {
launch {
dynamoDBService.addNicknameToDB(event.nicknameDto.memberId, event.nicknameDto.nickname)
}
}
}
DynamoDBEventListener 클래스의 경우, DynamoDB와의 비동기 통신을 위해 Dispatchers.IO를 사용하고 있다. 이 클래스는 CoroutineScope를 구현하고 있으며, CoroutineScope by CoroutineScope(Dispatchers.IO) 구문을 통해 모든 코루틴 작업을 Dispatchers.IO의 컨텍스트에서 실행하도록 지정한다.
따라서 insertNicknameToDynamoDB 함수 내에서 launch를 사용하여 addNicknameToDB suspend 함수를 호출할 때, 이 함수는 I/O 최적화된 스레드에서 실행되어, 네트워크 I/O 작업을 효과적으로 처리할 수 있다.
Dispatchers와 CoroutineScope에 대한 자세한 내용은 다음 링크에 상세하게 설명되어 있다.
코루틴과 suspend로 간단한 비동기 처리
코루틴과 suspend로 간단한 비동기 처리 📌 서론 이 글에서는 코루틴과 suspend 함수를 사용하여 복잡한 비동기 작업을 간단하게 처리하는 방법을 정리해보려고 한다. 코루틴(Coroutines) 기본 코루틴
yijoon009.tistory.com
실제 기능 검증
이제 실제로 로직을 실행해 보자!
프로젝트를 실행해 보니까 다음과 같은 NoSuchMethodError 에러가 발생했다.
Exception in thread "DefaultDispatcher-worker-2" java.lang.NoSuchMethodError: 'okhttp3.Request$Builder okhttp3.Request$Builder.tag(kotlin.reflect.KClass, java.lang.Object)' at aws.smithy.kotlin.runtime.http.engine.okhttp.OkHttpUtilsKt.toOkHttpRequest(OkHttpUtils.kt:51) at aws.smithy.kotlin.runtime.http.engine.okhttp.OkHttpEngine.roundTrip(OkHttpEngine.kt:49) at aws.smithy.kotlin.runtime.http.engine.internal.ManagedHttpClientEngine.roundTrip(ManagedHttpClientEngine.kt) at aws.smithy.kotlin.runtime.http.SdkHttpClient$executeWithCallContext$2.invokeSuspend(SdkHttpClient.kt:44) at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33) at kotlinx.coroutines.DispatchedTask.run(DispatchedTask.kt:108) at kotlinx.coroutines.scheduling.CoroutineScheduler.runSafely(CoroutineScheduler.kt:584) at kotlinx.coroutines.scheduling.CoroutineScheduler$Worker.executeTask(CoroutineScheduler.kt:793) at kotlinx.coroutines.scheduling.CoroutineScheduler$Worker.runWorker(CoroutineScheduler.kt:697) at kotlinx.coroutines.scheduling.CoroutineScheduler$Worker.run(CoroutineScheduler.kt:684) Suppressed: kotlinx.coroutines.internal.DiagnosticCoroutineContextException: [StandaloneCoroutine{Cancelling}@82ba480, Dispatchers.Default]
나와 동일한 에러가 aws-sdk-kotlin에 이슈로 등록되어 있었고 해결방법도 여기서 찾았다.
https://github.com/awslabs/aws-sdk-kotlin/issues/765
S3: putObject throws NoSuchMethodError exception · Issue #765 · awslabs/aws-sdk-kotlin
Describe the bug Simple code like this S3Client.fromEnvironment()..putObject { bucket = "myBucket" key = "myObject" body = ByteStream.fromString("myContent") } throws: java.lang.NoSuchMethodError: ...
github.com
답변 내용은 다음과 같다.

이 내용을 해석하자면 다음과 같다.
이 내용은 AWS SDK for Kotlin이 사용하는 HTTP 클라이언트로 OkHttp 5.0.0-alpha.10 버전을 사용한다는 사실과, 이로 인해 다른 버전의 OkHttp를 사용하는 소비자가 이진 호환성 문제(예: NoSuchMethodError 같은 에러)에 직면할 수 있음을 설명하고 있다. 이는 의존성 불일치가 흔한 문제임을 보여주며, 소비자가 이 문제를 해결할 수 있는 몇 가지 일반적인 해결책을 제시한다.
1. 의존성 버전 일치: 가장 간단한 해결책은 명시적인 의존성(예: OkHttp)의 버전을 다른 의존성(예: AWS SDK for Kotlin)이 사용하는 버전과 일치시키는 것이다. 이는 build 설정에서 version.strictly를 제거하는 것만큼 간단할 수도 있고, Gradle 내의 다른 버전 제어 메커니즘을 사용하는 것을 포함할 수도 있다. 하지만, 서로 호환되지 않는 전이적 의존성을 가진 여러 의존성(예: AWS SDK for Kotlin은 OkHttp 5.0.0-alpha.10이 필요, 다른 서드파티 라이브러리는 다른 버전 필요)을 다룰 때는 이 방법이 불가능할 수도 있다.
2. 의존성 음영 처리: Gradle Shadow 플러그인을 사용하여 의존성을 함께 번들링 하고(예: AWS SDK for Kotlin 및 모든 의존성), 잠재적으로 충돌하는 의존성(예: OkHttp)을 새로운 네임스페이스로 이동시켜 여러 버전의 의존성을 동시에 포함할 수 있게 하는 uber JAR를 빌드할 수 있다. 이를 통해 충돌 없이 여러 버전의 의존성을 동시에 포함시킬 수 있다.
또한, AWS SDK for Kotlin은 현재 OkHttp를 다운그레이드할 계획이 없으며, 프리-프로덕션 개발(즉, GA/1.0 이전) 동안 새로운 버전의 의존성을 적극적으로 채택할 계획임을 명시하고 있다. GA 이후에는 의존성과 버전 전략을 식별하는 지원 매트릭스를 정의할 예정이다.
간단히 말해 NoSuchMethodError가 발생한 원인은 AWS SDK for Kotlin과 프로젝트에서 사용하는 OkHttp 버전 사이의 불일치 때문에 발생하는 것이다. 해결책으로는 의존성 버전을 일치시키거나, 의존성 음영 처리를 사용해 충돌을 방지하는 방법 등이 있다.
이러한 상황에서 의존성 버전 맞추기를 시도해 보려면, 먼저 프로젝트의 build.gradle.kts 파일에 OkHttp의 5.0.0-alpha.10 버전을 명시적으로 지정해야 한다:
dependencies {
// 기존 의존성...
// OkHttp 버전을 AWS SDK for Kotlin이 사용하는 버전으로 업데이트
implementation("com.squareup.okhttp3:okhttp:5.0.0-alpha.10")
}
이렇게 진행하면 NoSuchMethodError 에러가 해결된다!!
이제 진짜로 다시 로직을 실행해 보자!
일단 성공 로그는 다음과 같이 출력된다.

그리고 AWS DynamoDB 콘솔에서도 실제로 데이터가 잘 들어갔는지 확인해 보자.
DynamoDB에서 왼쪽 [항목 탐색] 메뉴에 들어간다. 그럼 왼쪽에 테이블 목록이 나온다.

테이블 목록에서 내가 확인할 테이블을 선택하면 해당 테이블의 항목 목록이 보인다.

그리고 잘 보면 아까 로그에 찍힌 회원의 정보(memberId: 41, nickname: nickname17)가 잘 들어간 게 확인된다.
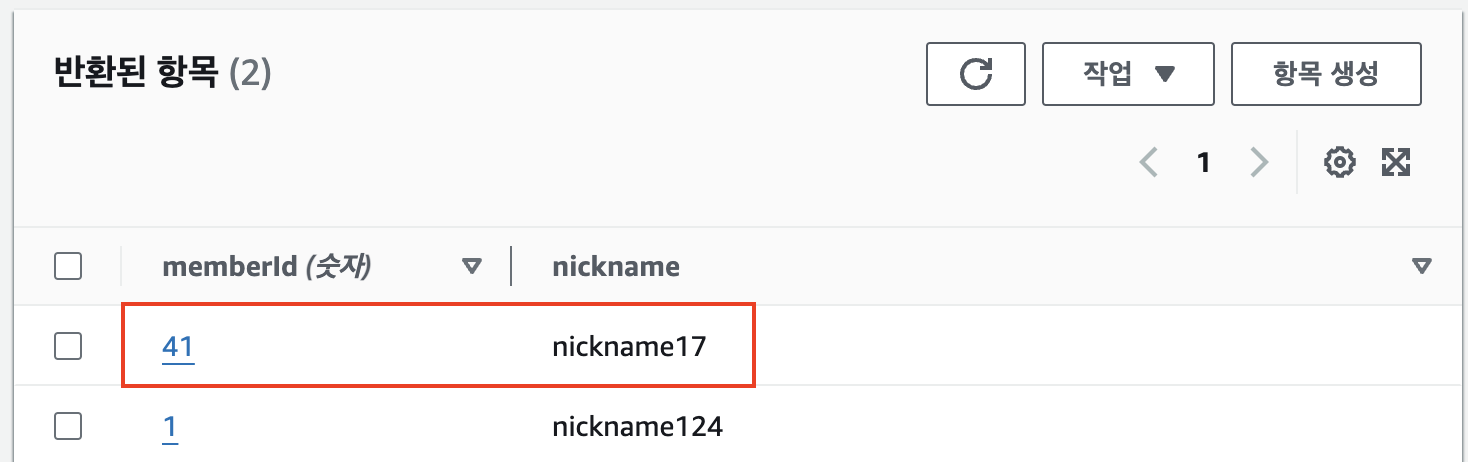
만약에 왼쪽 메뉴에서 [테이블] 메뉴로 들어가서 member_nickname 테이블로 들어가면 [항목 요약] 부분에 데이터가 안 들어간 것처럼 보인다. (원래 1개 있었는데 방금 내가 스프링 부트에서 항목을 하나 더 추가했는데 화면에 나오는 항목 수는 1이다.)

이런 이유는 'DynamoDB는 약 6시간마다 다음 정보를 업데이트합니다.'라는 문구를 통해서 아직 업데이트가 안 됐기 때문에 방금 추가한 항목의 개수가 추적인 안된 숫자라는 걸 알 수 있다.
여기서 [라이브 항목 수 가져오기]를 클릭하면 팝업이 뜬다

이 팝업에서 아까는 항목 수 1이었던 게 2로 나타나는 모습을 볼 수 있다!
이렇게 코틀린과 스프링 부트를 이용해서 DynamoDB에 항목을 추가하는 프로세스를 같이 살펴봤다!
사이드 팀원인 "개발자의 서랍"님의 블로그도 한번 방문해 보세요! 좋은 글이 많이 있습니다 :)
개발자의 서랍
[기록 implements 기억] 모든것을 기록하며 공유하는 주니어 백엔드 개발자
curiousjinan.tistory.com
'프로그래밍 언어 > Kotlin(코틀린)' 카테고리의 다른 글
| 코루틴과 suspend로 간단한 비동기 처리 (2) | 2024.02.27 |
|---|---|
| 코틀린과 스프링 부트 3에서 Feign Client 적용하기 (1) | 2024.02.26 |